
请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载
请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载

ThinkSound 是阿里通义实验室推出的音频生成模型,致力于让 AI 像“专业音效师”一样,根据视频内容自动生成自然、真实且贴合画面的音频。它为影视后期与游戏开发提供了高效的音频自动生成解决方案,能够精准匹配环境音、动态变化音效与复杂音频场景,极大提升了多模态内容创作效率与质量。
开源地址:https://github.com/FunAudioLLM/ThinkSound
☞☞☞☞☞☞ 一键启动包在右侧下载 ☞☞☞☞☞☞
视频介绍:
配置要求:
电脑满足以下配置:
- 操作系统:Windows 10/11 64位
- 内存:20G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡,30系及以上显卡
- CUDA:显卡驱动更新到最新后,支持的CUDA版本大于等于12.8版本(如不知道显卡支持的CUDA版本,可点击此链接查看:https://aiyy.info/supported-cuda-versions/)
- 整合包解压完约52.8G,要留足硬盘空间
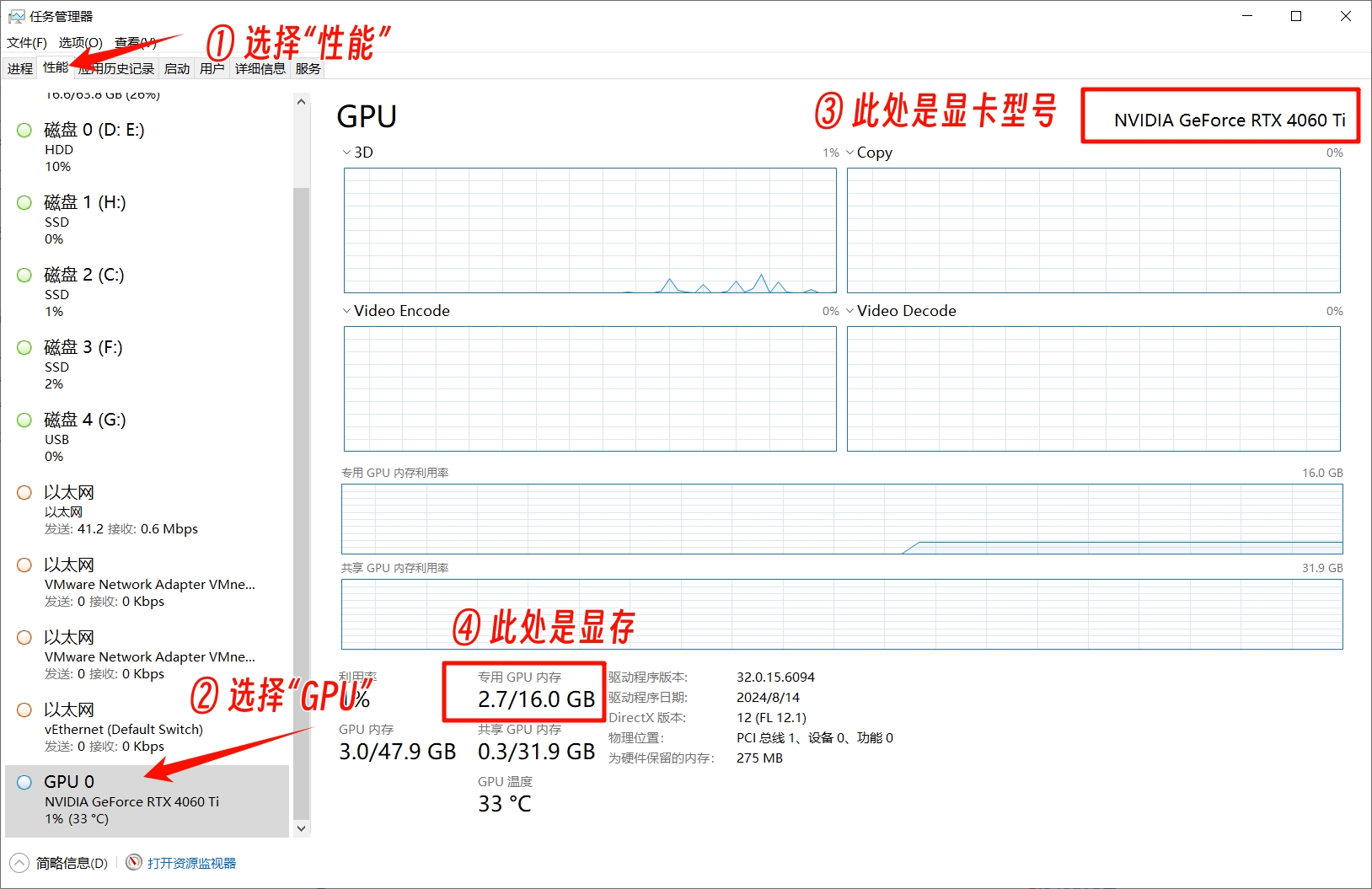
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
① 打开下载页面(https://aiyy.info/thinksound/)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
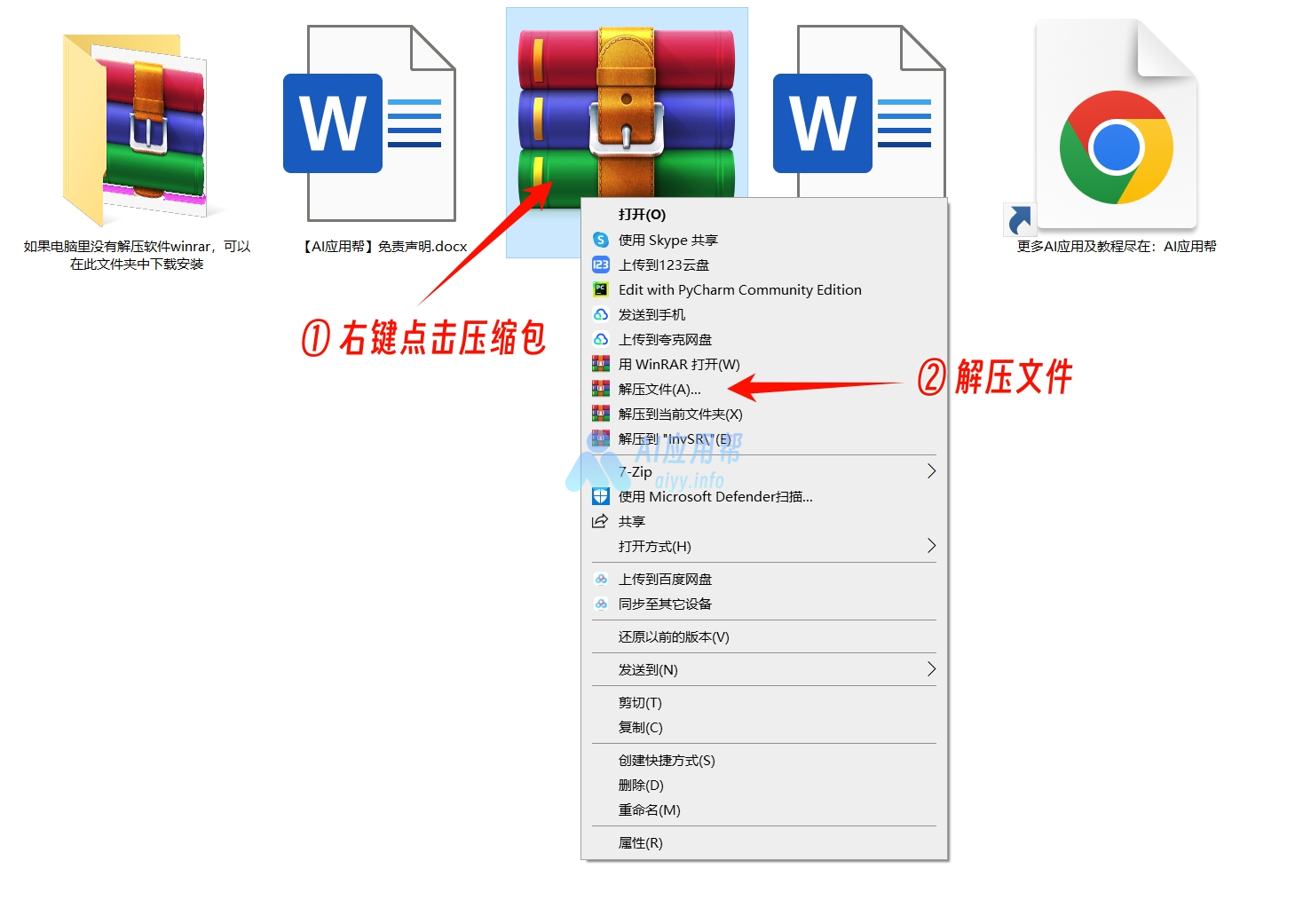
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

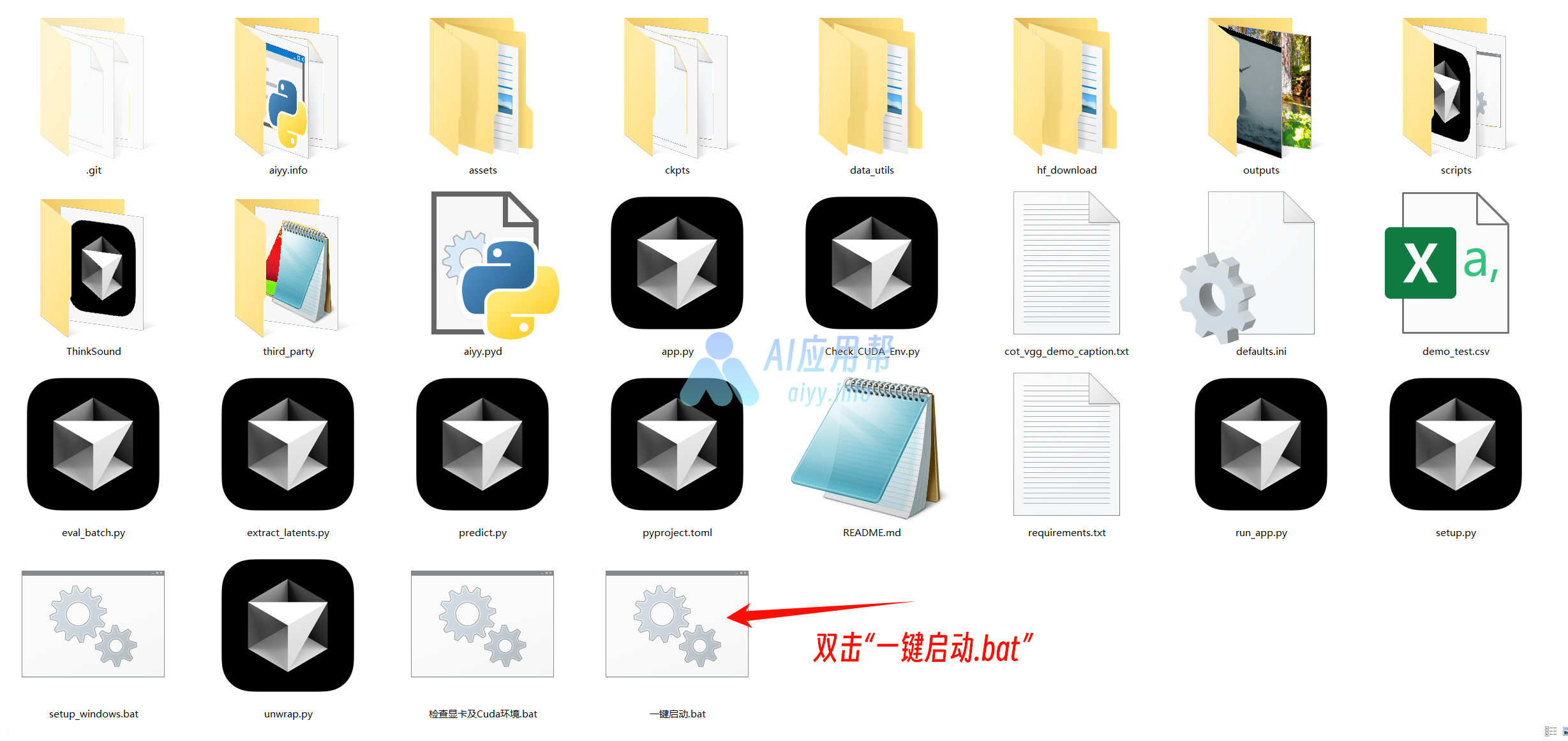
② 双击“一键启动.bat”,稍等片刻会在浏览器中自动打开操作界面
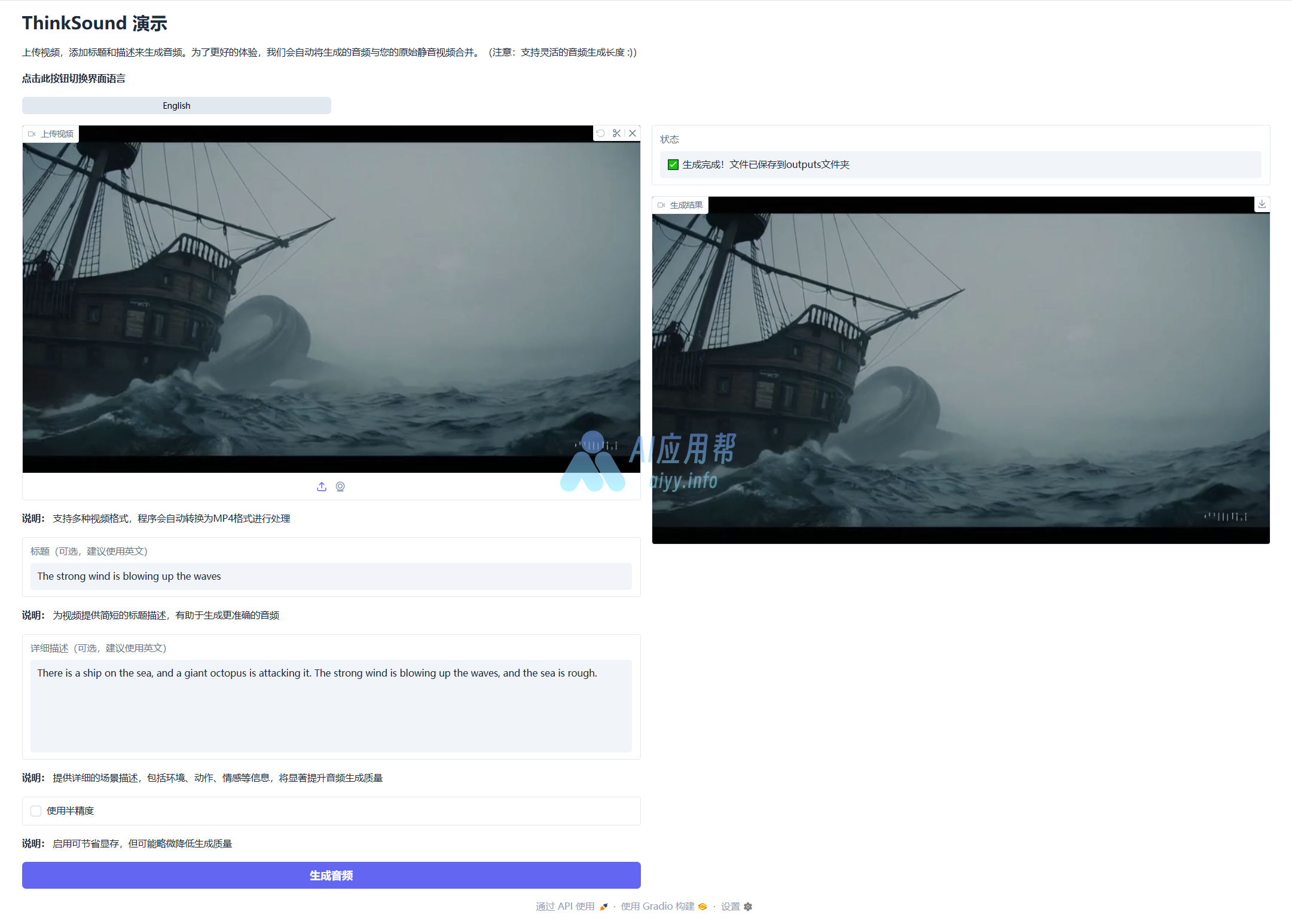
③ 上传视频,输入标题及详细描述(建议用英文),也可以留空,程序会自动识别视频内容并配音,最后点击“生成音频”,生成结果位于右侧
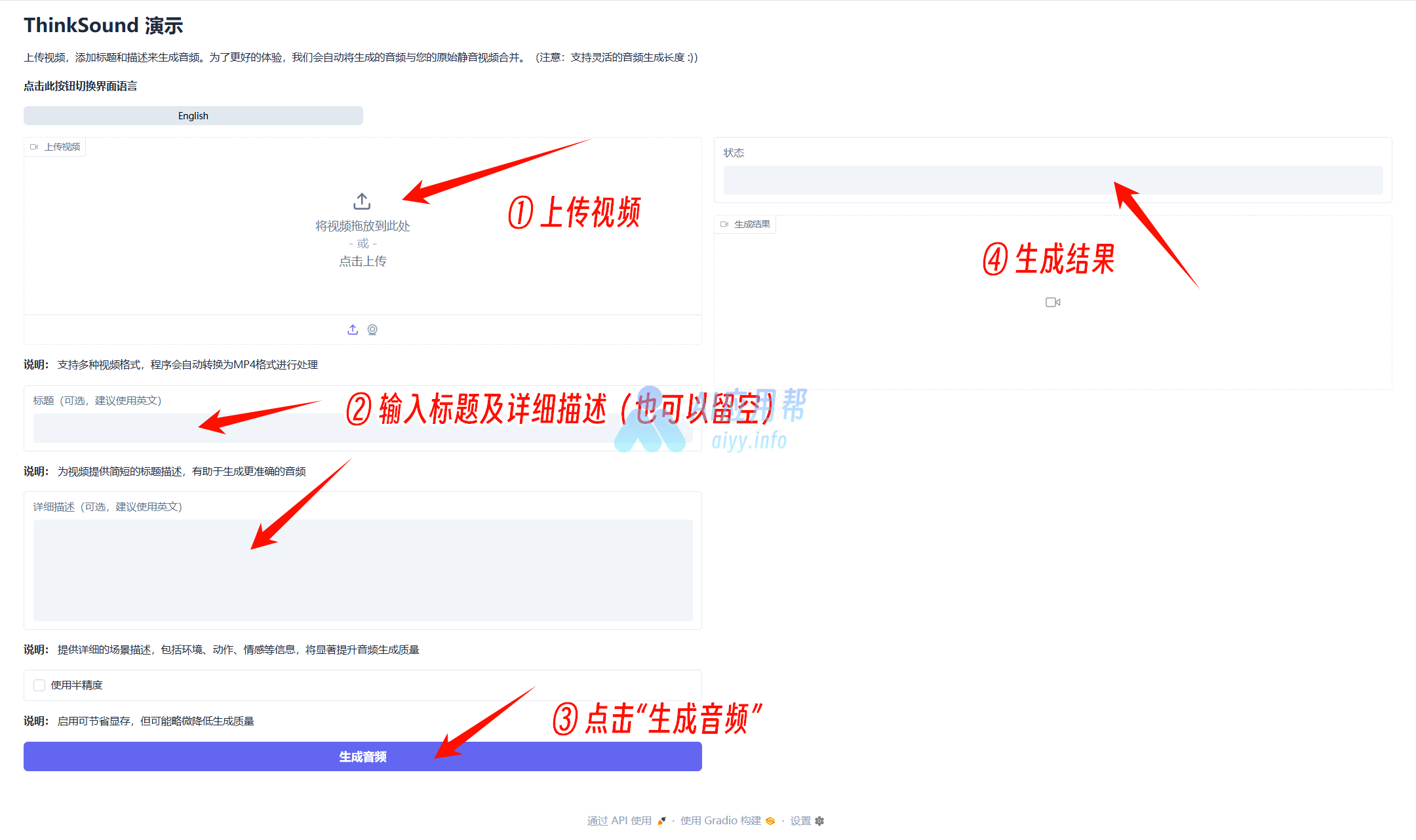
如下方示例所示
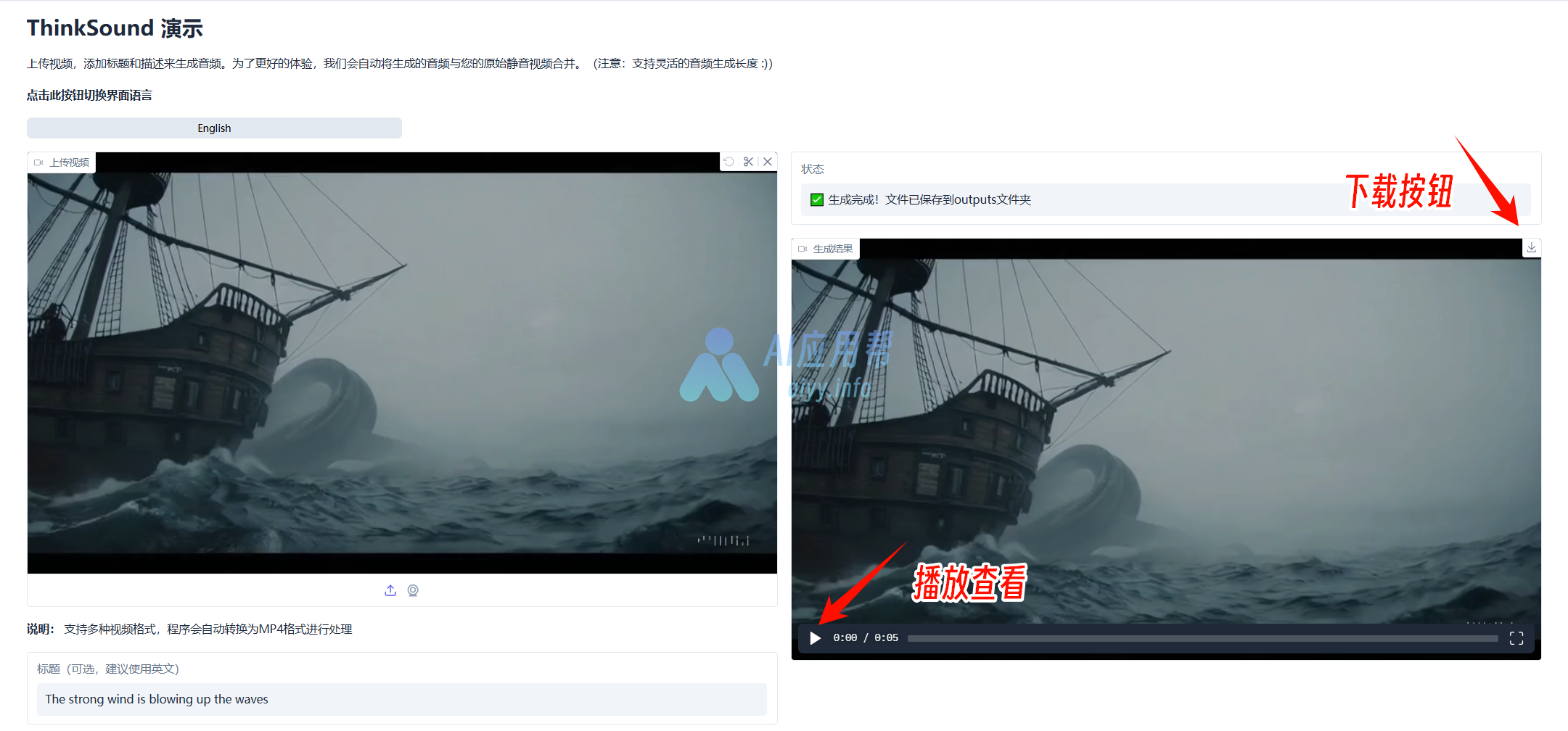
可以播放查看,点击右上角下载按钮可以保存至指定文件夹
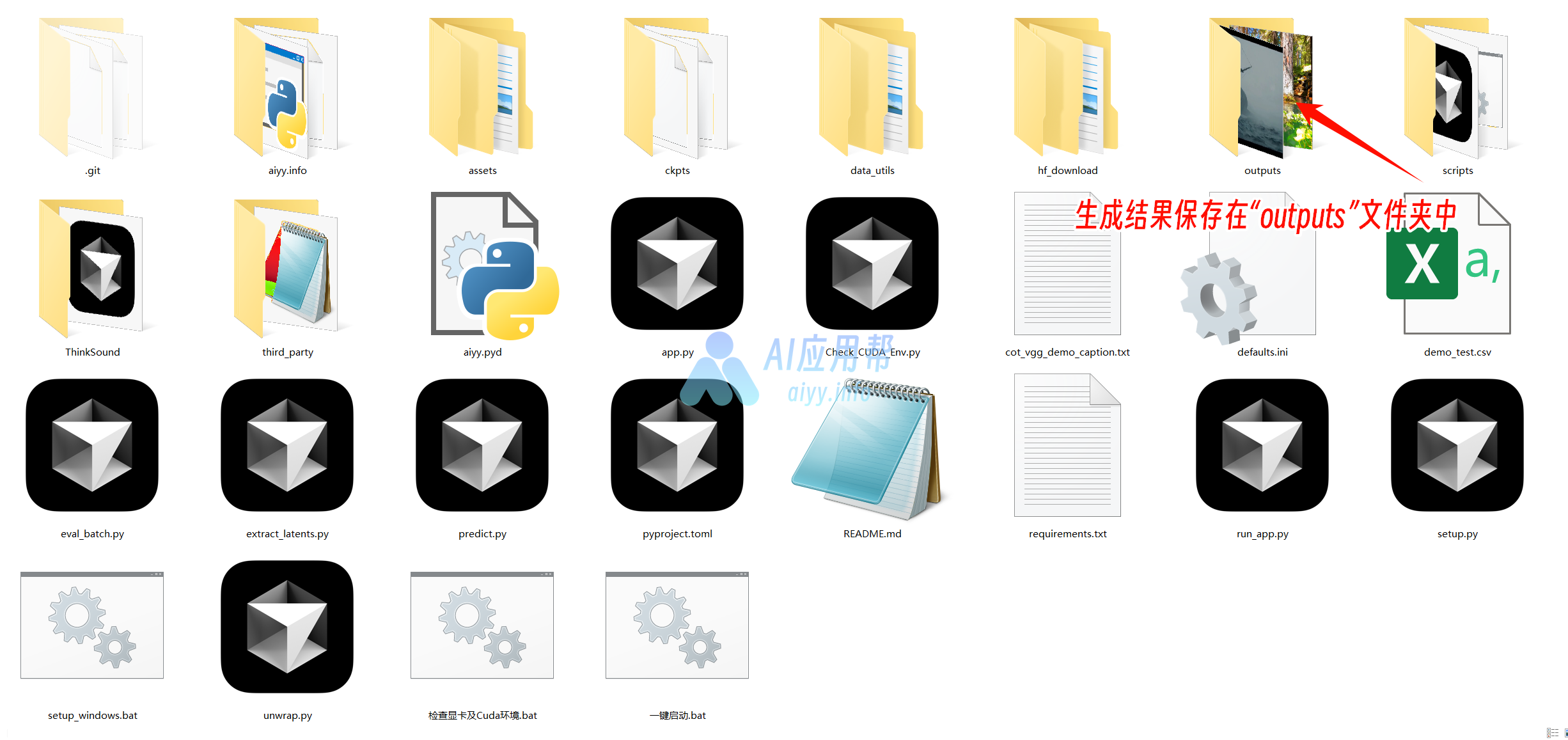
④ 生成结果也会保存在文件包中的“outputs”文件夹中
声明:
① 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考赞助计划。
② 本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

