
请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载

GPT-SoVITS 项目通过先进的声音合成技术,进行音色克隆,并根据文本生成音频文件。该项目的核心技术突破,使得声音克隆和文本到语音(TTS)转换变得更加精准和自然,即使仅有极少的声音样本。
开源地址:https://github.com/RVC-Boss/GPT-SoVITS
☞☞☞☞☞☞ 一键启动包在右侧下载 ☞☞☞☞☞☞
原音频:
克隆音色后生成的音频:
软件功能
- 零样本文本到语音(TTS):即使只有5秒的声音样本,GPT-SoVITS 也能将文本转换为与样本声音相同的语音,这在TTS技术领域是一个巨大的突破。
- 少样本TTS:通过提供1分钟的声音样本,系统能够生成非常自然、真实的声音克隆。这使得即便是短暂的录音,也能被用于创建高保真度的声音模型。
- 多语言转换:该技术支持将英语、日语、汉语等多种语言的文本转换为指定的声音克隆,展现了其在全球范围内的广泛应用潜力。
- 易用的Web界面:GPT-SoVITS 提供了一个友好的Web界面,即使是技术新手也可以轻松操作,进行声音克隆和TTS转换。
应用场景
- 个性化语音助手:通过少量声音样本,用户可以定制出具有自己声音或亲友声音的语音助手,增强互动体验。
- 配音与影像制作:为动画、电影、游戏等创作中的角色定制独特的语音,快速完成高质量的配音工作。
- 语音合成与翻译:通过将文本转换为目标语言的克隆声音,提供多语言语音合成与翻译服务,在跨语言交流中展现巨大潜力。
- 教育与培训:定制名人或专家的语音克隆,用于教育内容或培训材料,增加学习的趣味性和参与感。
- 语音备份与恢复:为需要保存或恢复特定声音的个人或机构提供解决方案,例如保护逝去亲人的声音或恢复损坏的录音。
配置要求:
建议电脑满足以下配置:
- 操作系统:Windows 10/11 64位
- 显卡:至少8G显存的英伟达(NVIDIA)显卡
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小

使用教程:
① 打开下载页面(https://aiyy.info/gpt-sovits/)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件下载地址:https://www.winrar.com.cn/)
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

② 双击“go-webui.bat”,稍等片刻会自动打开操作界面
③ 素材预处理
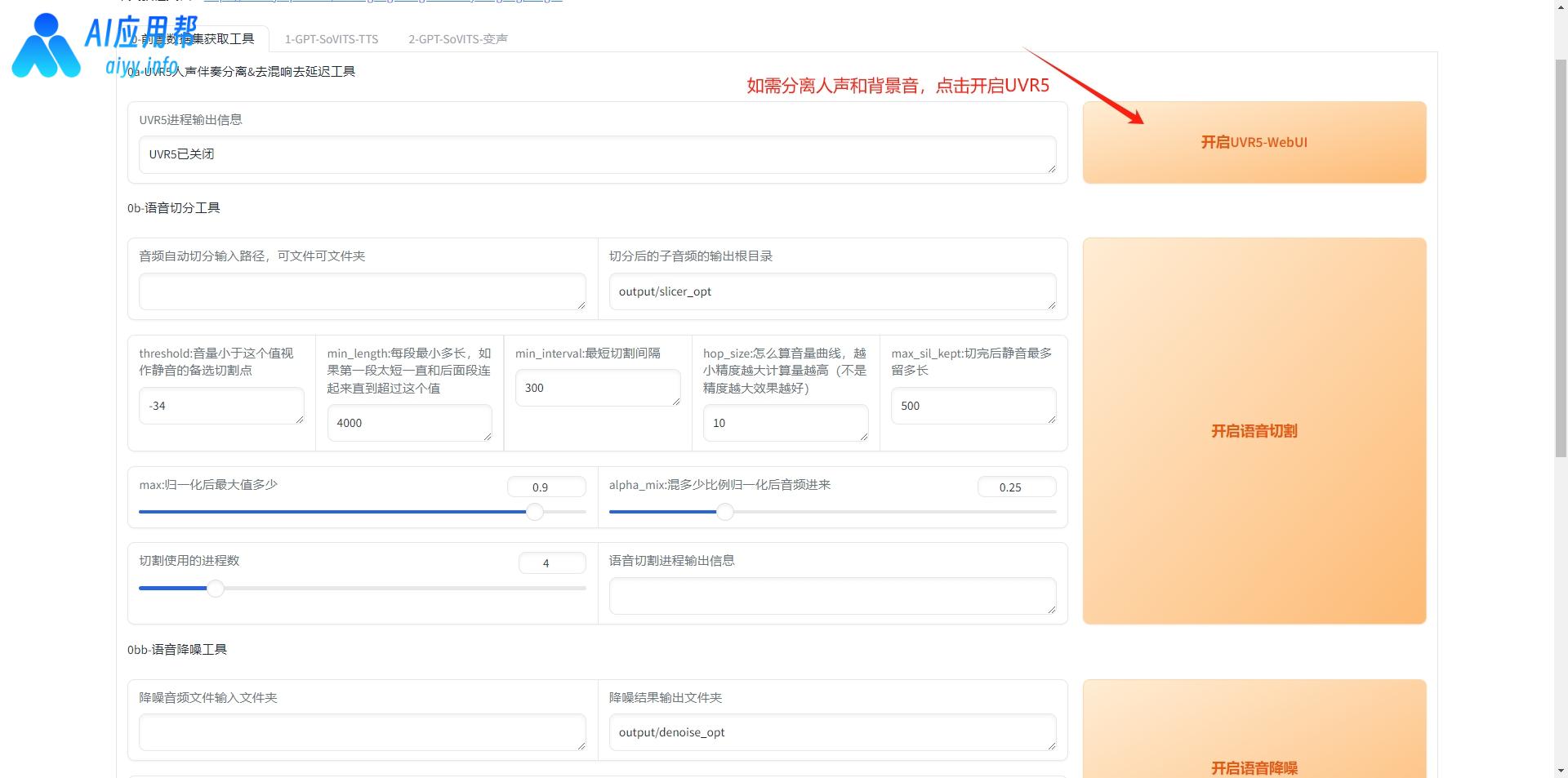
1、提取干声:准备1分钟左右的音频素材,音频需要是单个人说话的音频,没有噪音、没有配音、没有背景音乐的干声,如需分离人声和背景音,可以打开UVR5进行人声伴奏分离,并且去混响,去延迟。
点击“开启UVR5-WebUI”,稍等片刻,会自动打开另一个操作界面
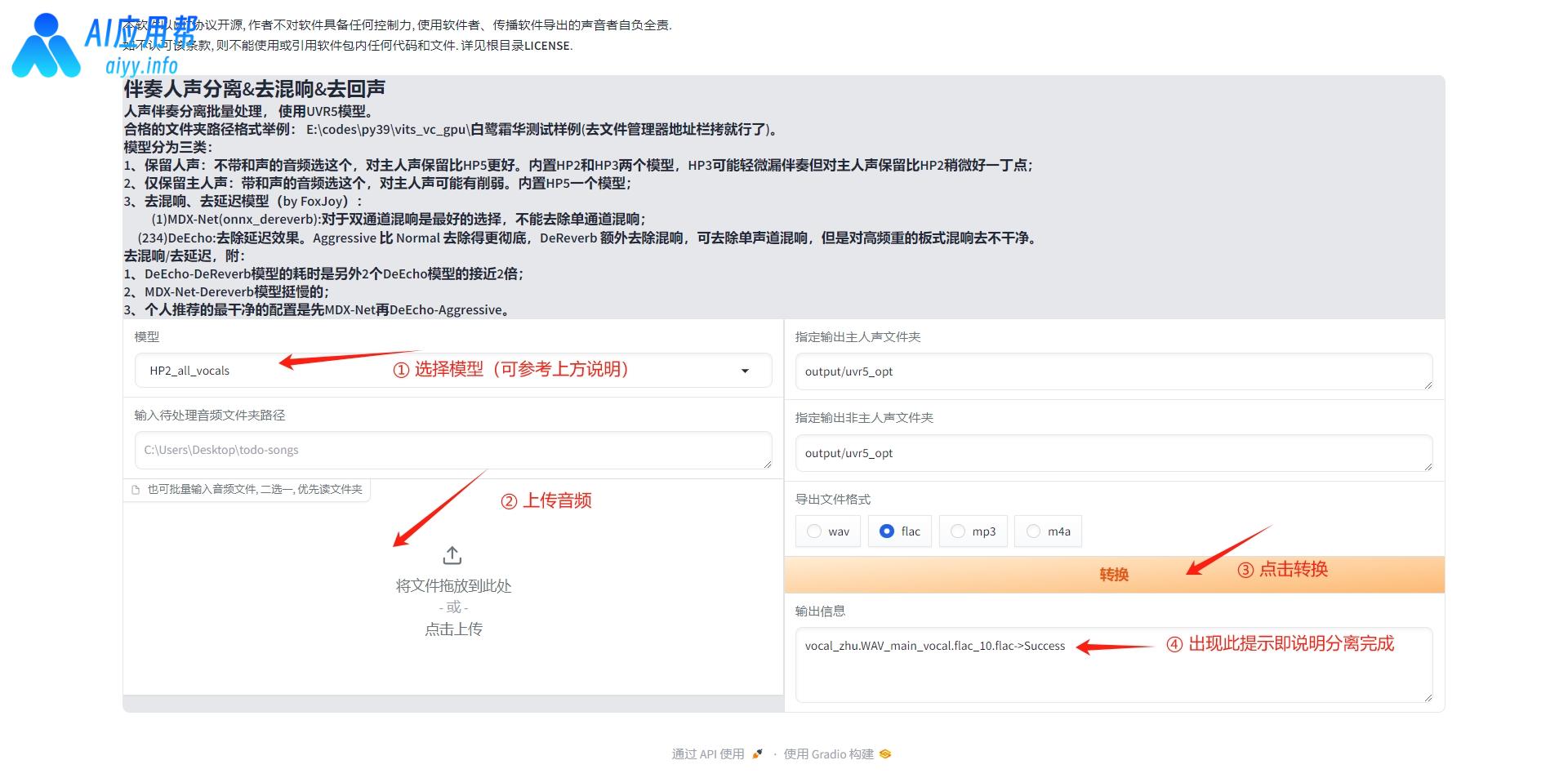
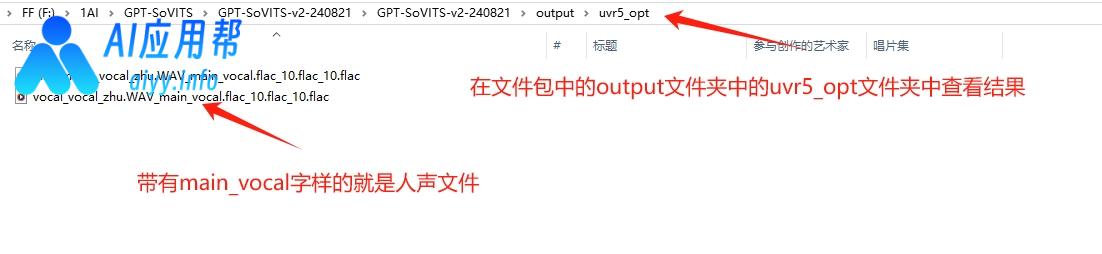
先选择模型,操作界面上方有说明,可以根据说明进行选择,然后上传音频,点击“转换”,程序运行完成后,右下方输出信息框会提示分离完成,在文件包中的“output”文件夹中的“uvr5_opt”文件夹中可以查看到结果,带有main_vocal字样的就是人声文件,可以将分离完成后的文件再次上传,选择不同的模型再次分离,最终生成只有人声的音频
分离操作完成后,关闭UVR5,否则会占用显存
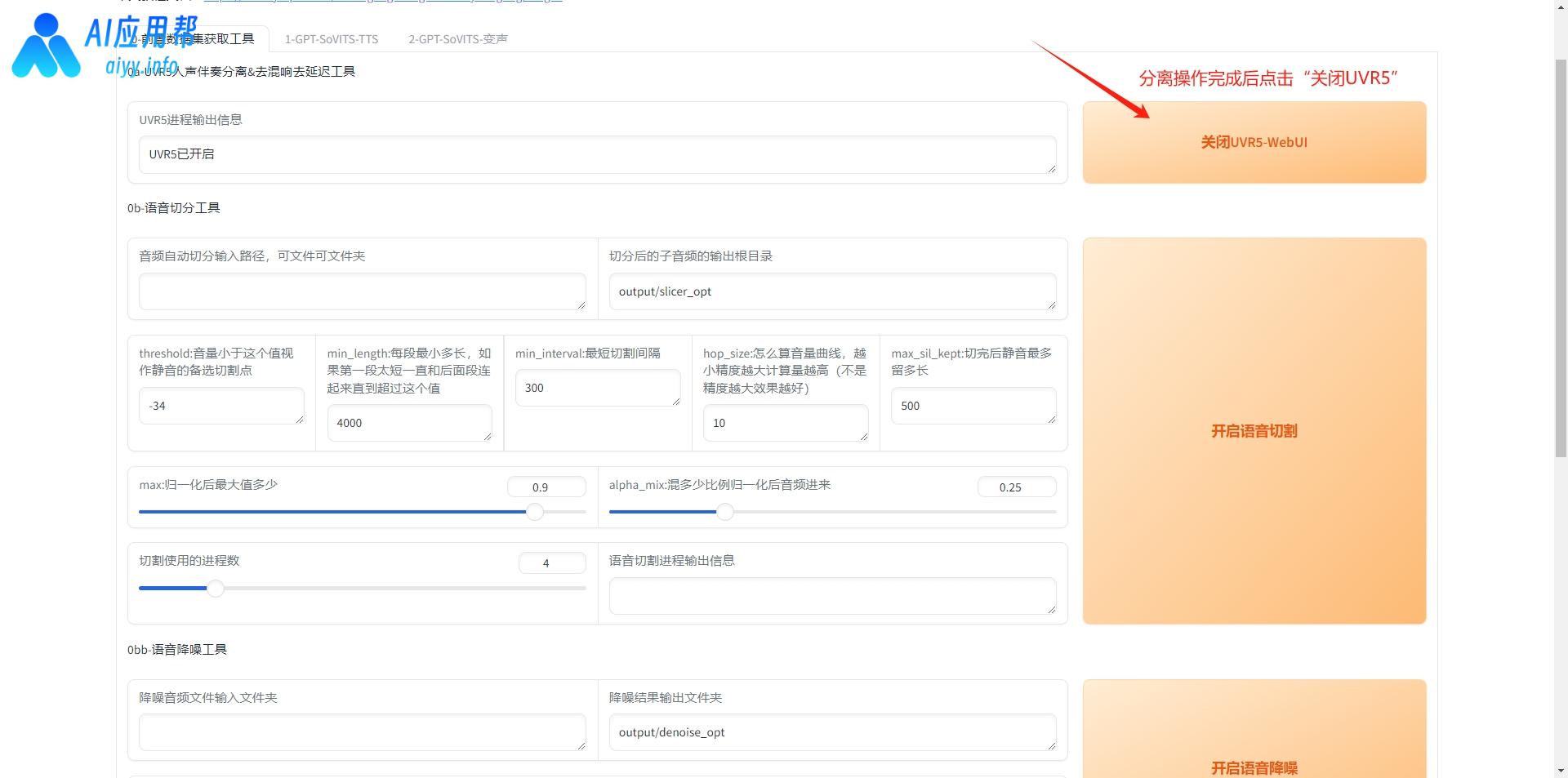
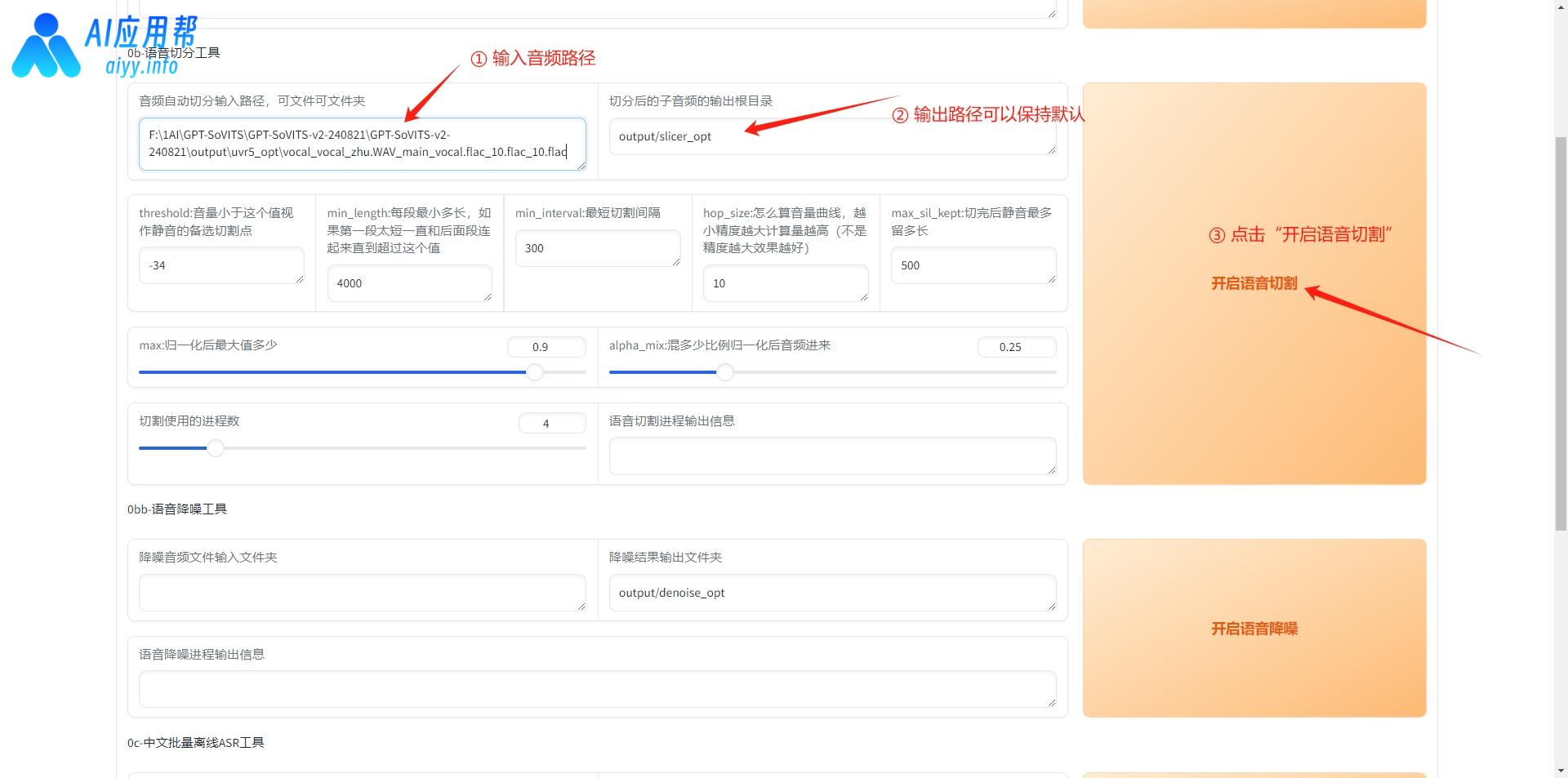
2、音频切割:将长音频文件切割成若干段短的音频,方便后续处理。在路径框中输入音频路径,如果文件夹中只有用于克隆的音频文件,也可以填写文件夹路径,输出路径保持默认即可,然后点击“开始语音切割”,切割完成后,在输出信息中会提示切割结束。
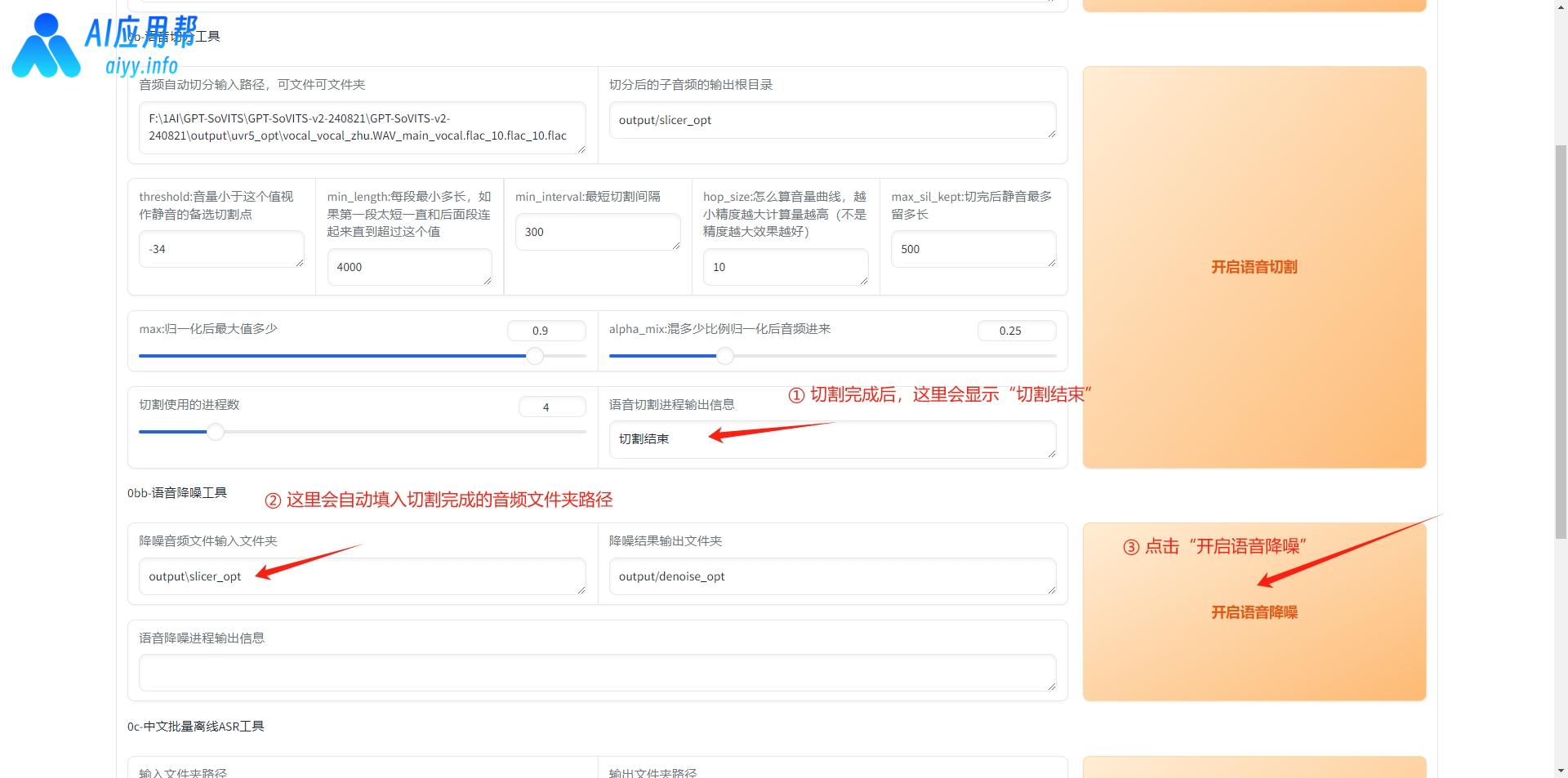
3、语音降噪:语音切割完成后,在语音降噪区会自动填入切割完成的音频文件夹路径,点击“开启语音降噪”即可
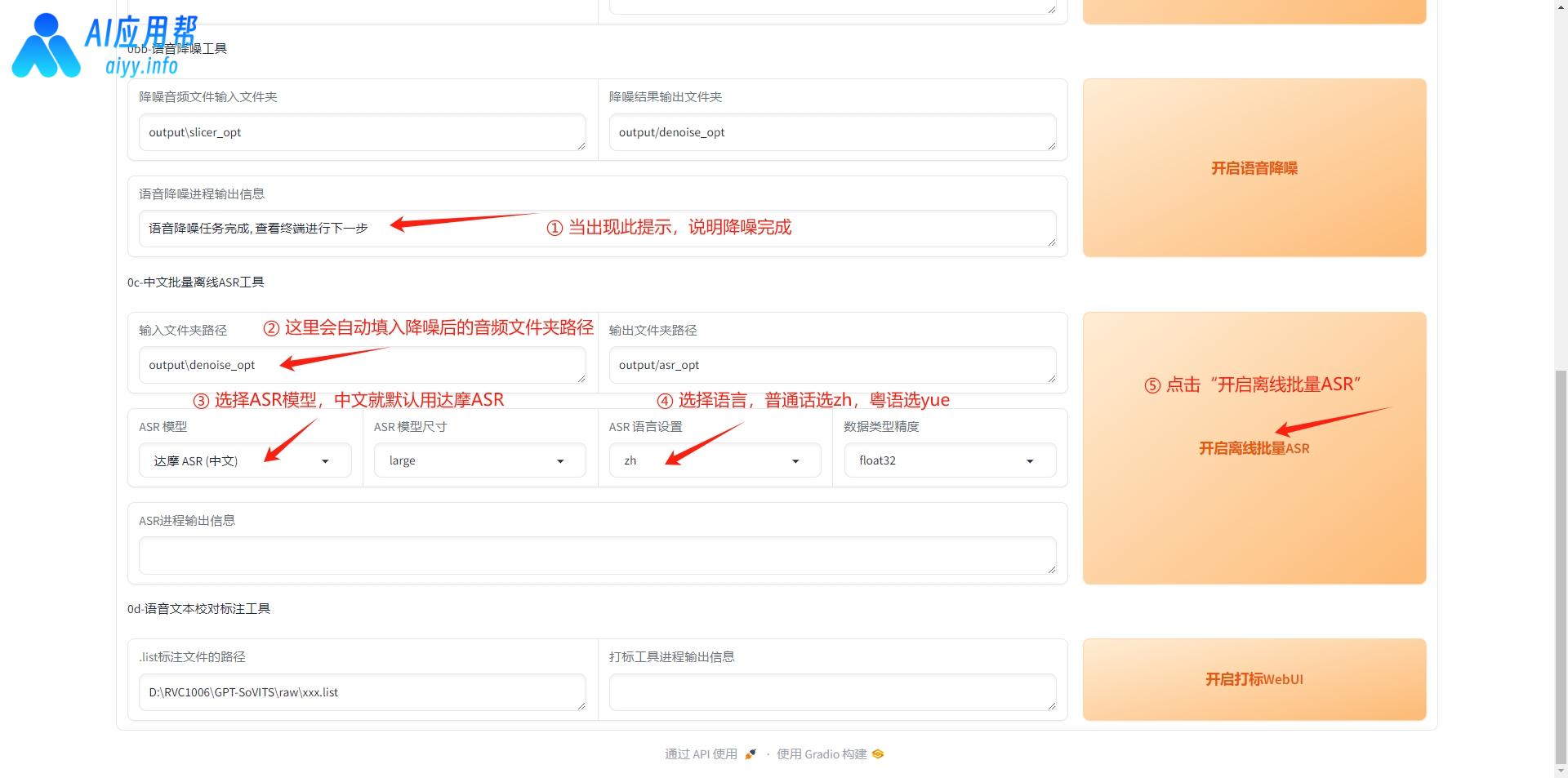
4、ASR处理:就是生成音频文件对应的文字,然后生成一个带有声音文件地址,对应文字内容,对应语言类型的清单,保存在一个xxx.list的文本文件里面。
降噪完成后,在ASR工具区会自动填入降噪后的音频文件夹路径,选择ASR模型,中文就默认用“达摩ASR”,英文等其他语种可以用“Faster Whisper”,然后选择语言,普通话选zh,粤语选yue,最后点击“开启离线批量ASR”,处理完成后在输出信息中会提示ASR任务完成。
5、语音文本校对:检查生成的文本和音频是否一致。
ASR任务完成后,在语音文本校对区会自动填入生成list文件路径,点击“开启打标WebUI”,稍等片刻会打开一个新的操作界面。
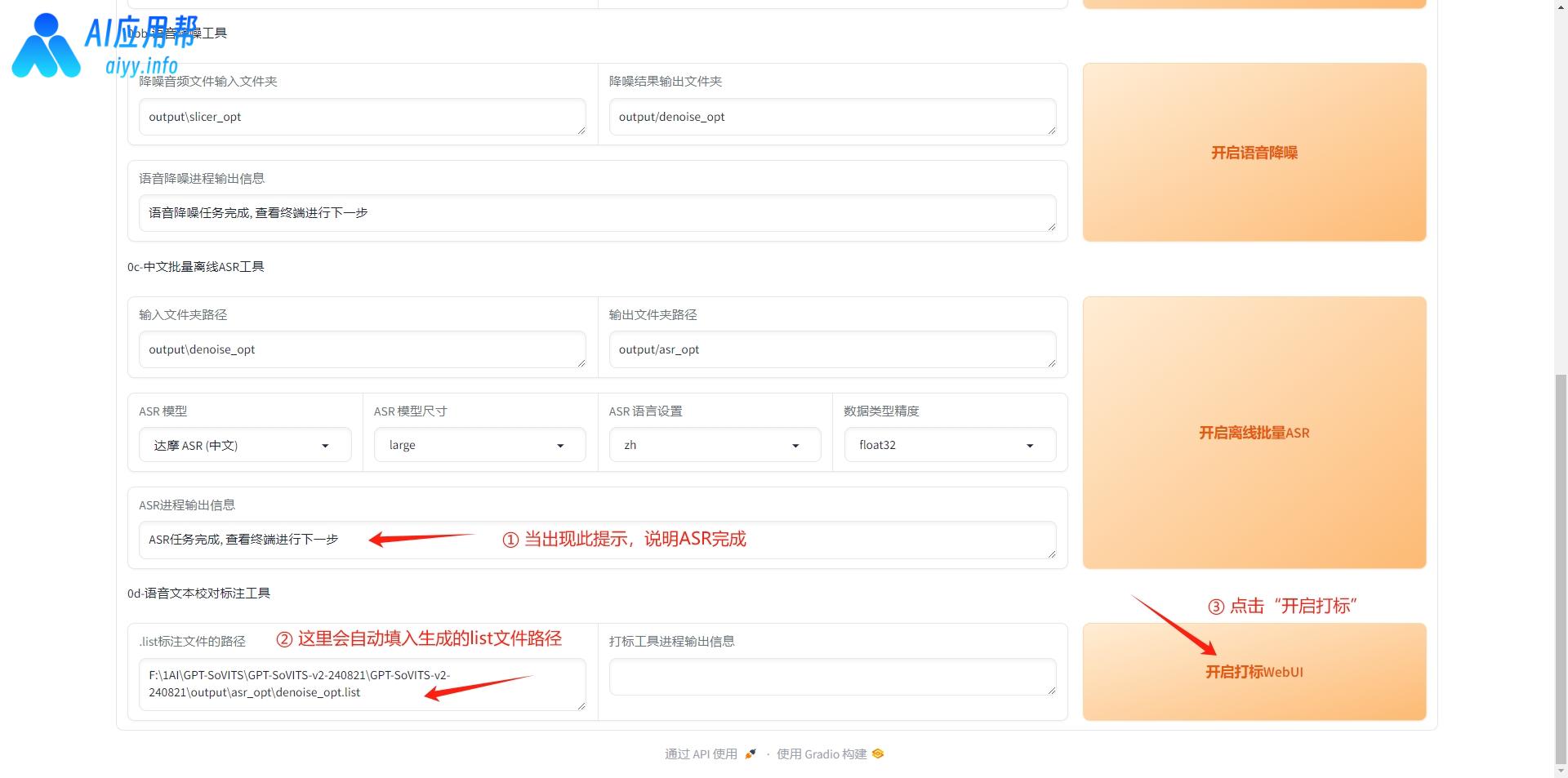
检查左边的文字和右边的音频是否一致,如有不对应的地方,可以手动修改,将正确的文本输出进文本框中
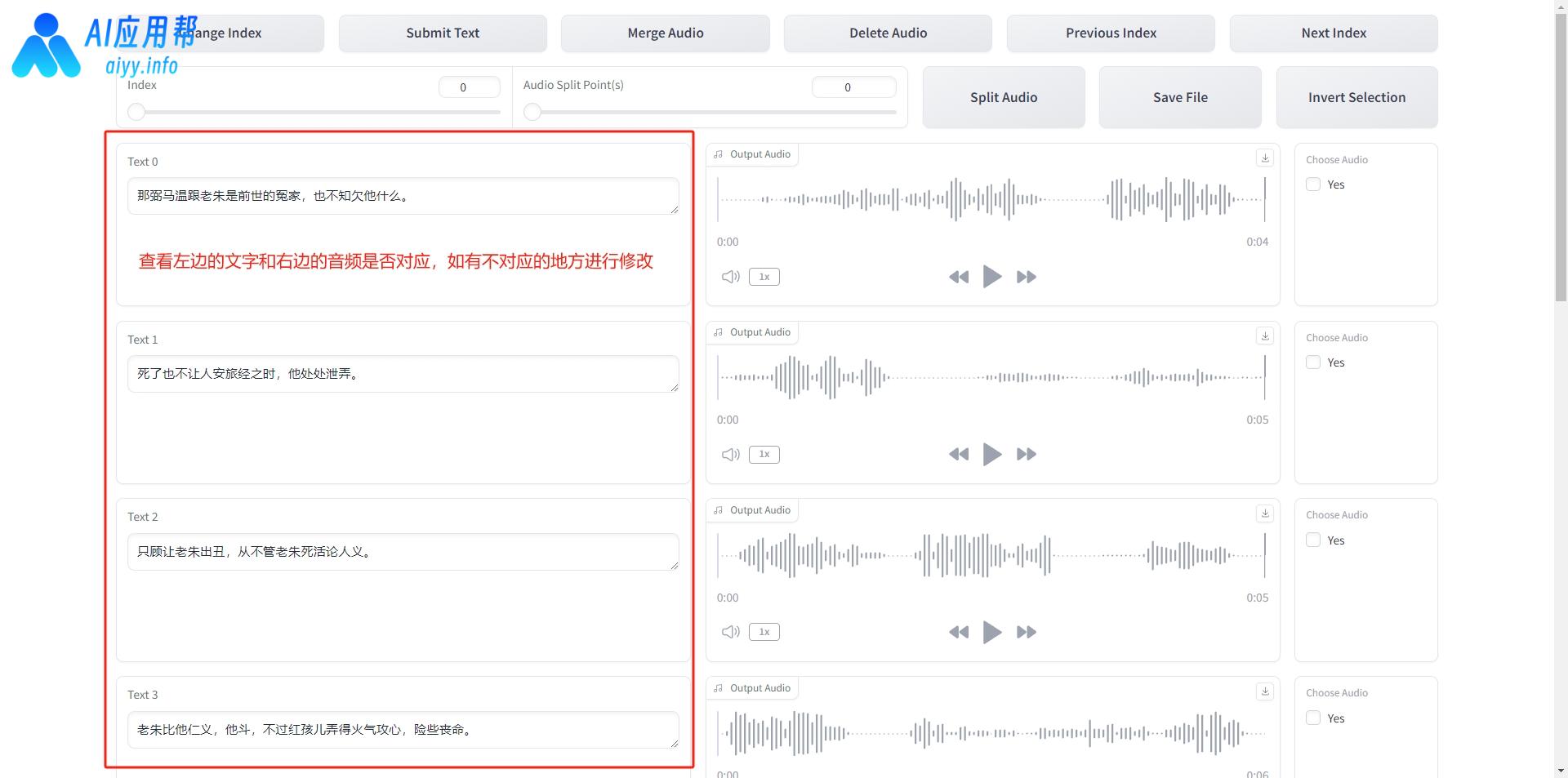
如内容比较多,可以按翻页按钮进入下一页,调整完成后点击“Save File”保存,然后就可以关闭这个页面,回到之前的操作界面。
④ 模型训练并微调
1、数据格式化:素材预处理完成之后,接下来是对生成的数据进行格式化。
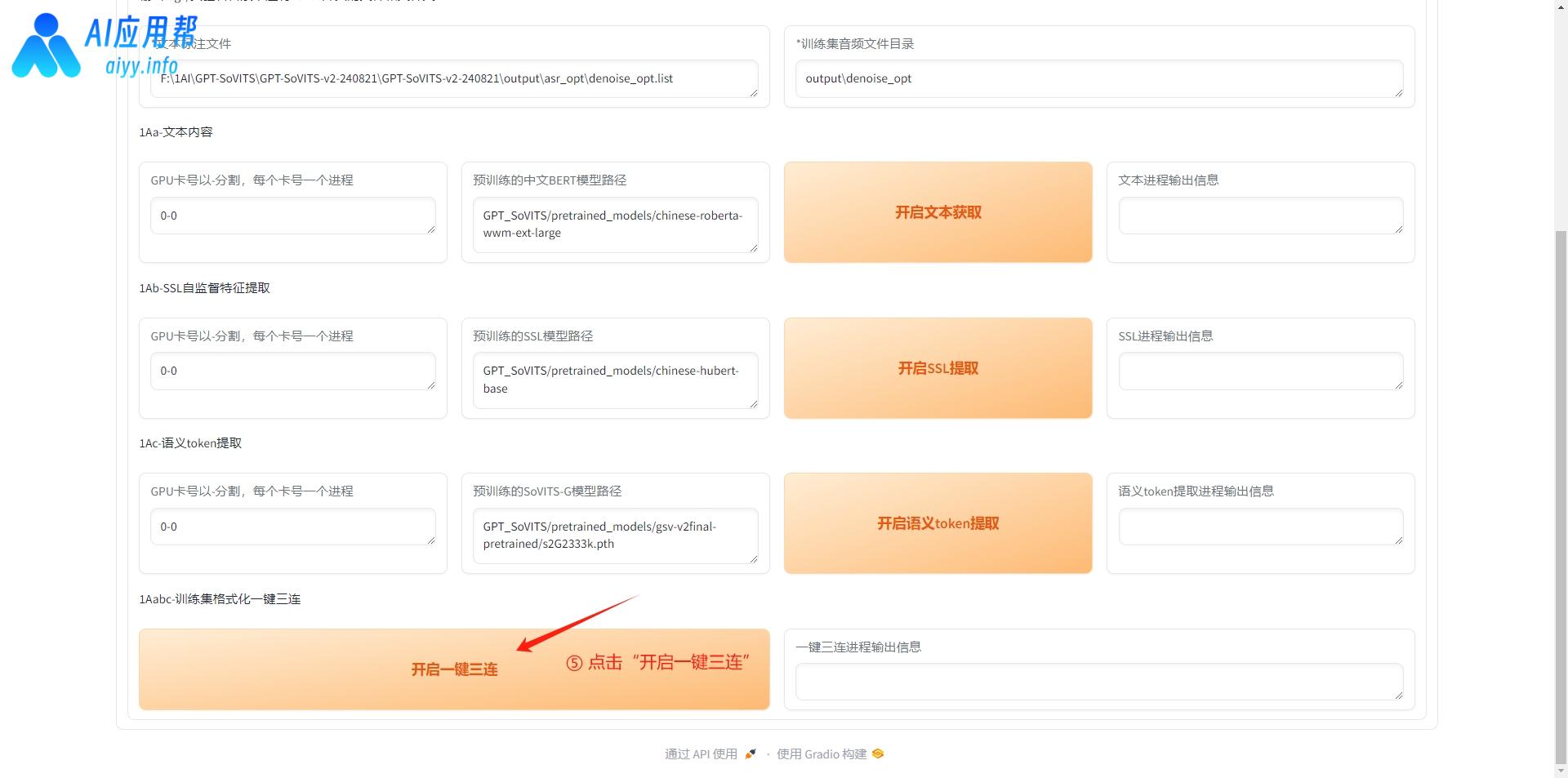
返回之前的操作界面,点击“1-GPT-SoVITS-TTS”这个标签页,切换之后,需要给模型取个名字(英文或数字),版本选择V2,相关路径会自动填充,如无特殊要求,保持默认即可。
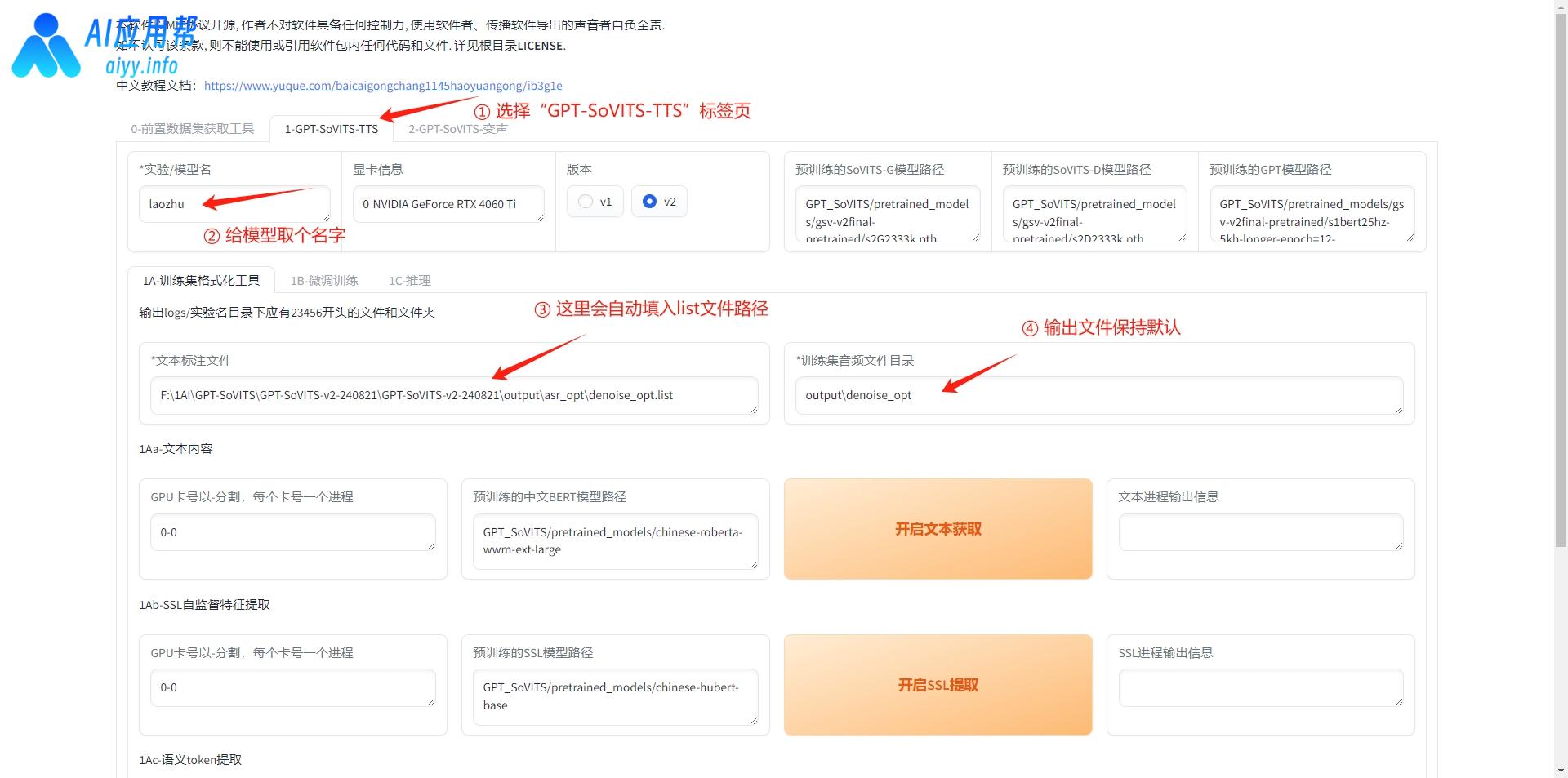
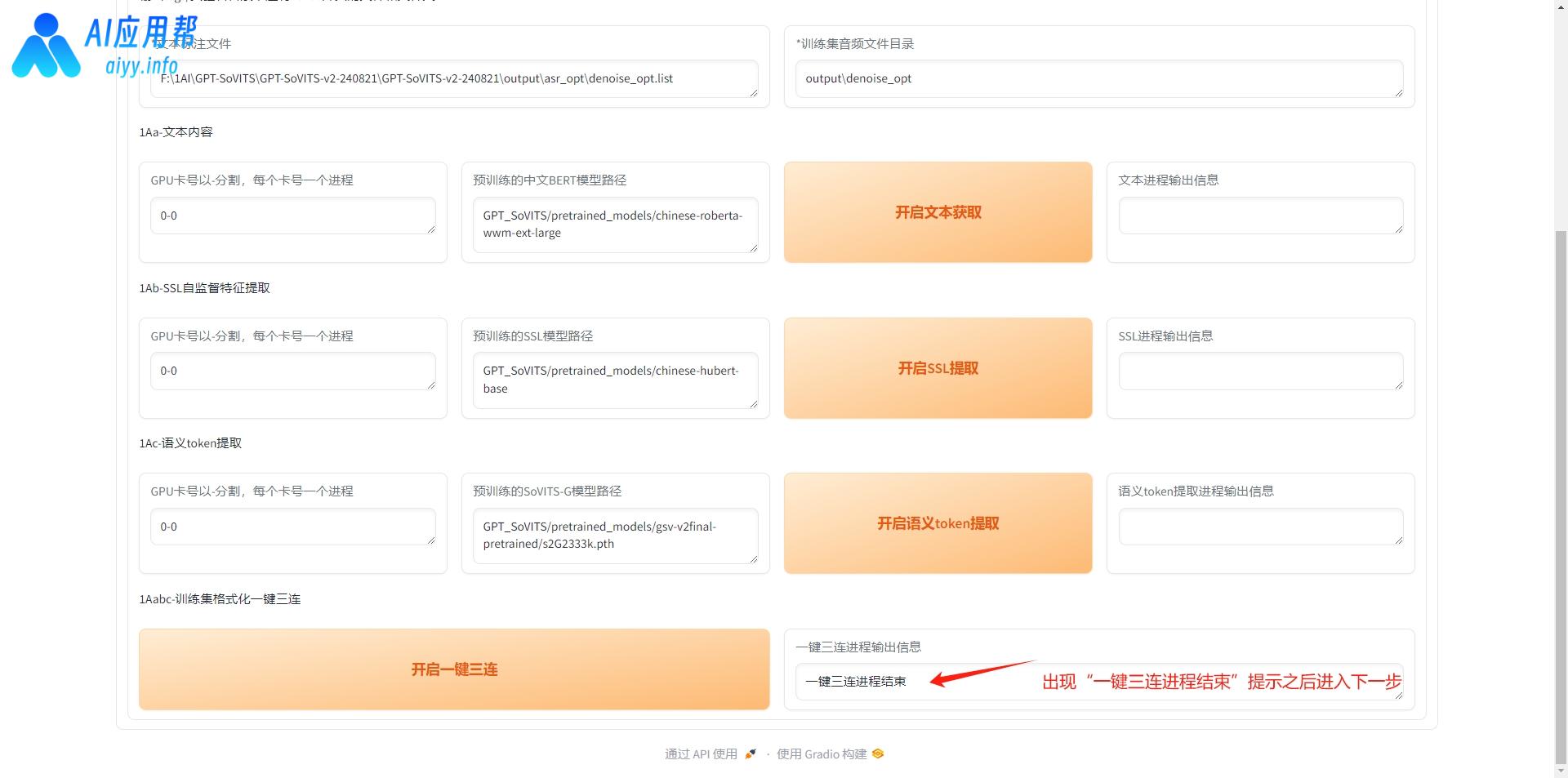
滑到页面最下方,点击“开启一键三连”,当右侧输出信息提示“一键三连进程结束”,再开始下一步。
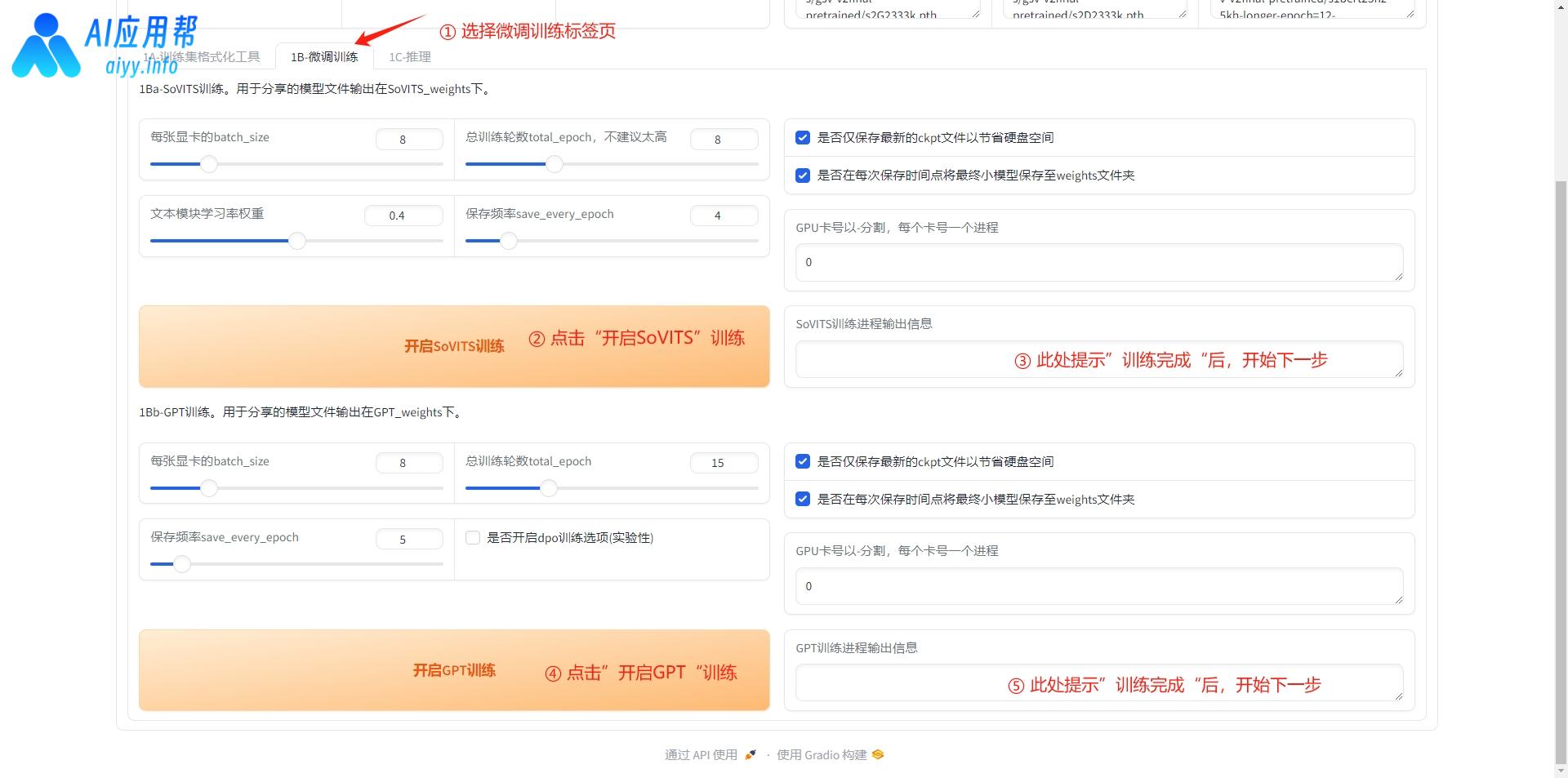
2、微调训练:基于预训练模型的微调训练,需要进行SoVITS训练和GPT训练。
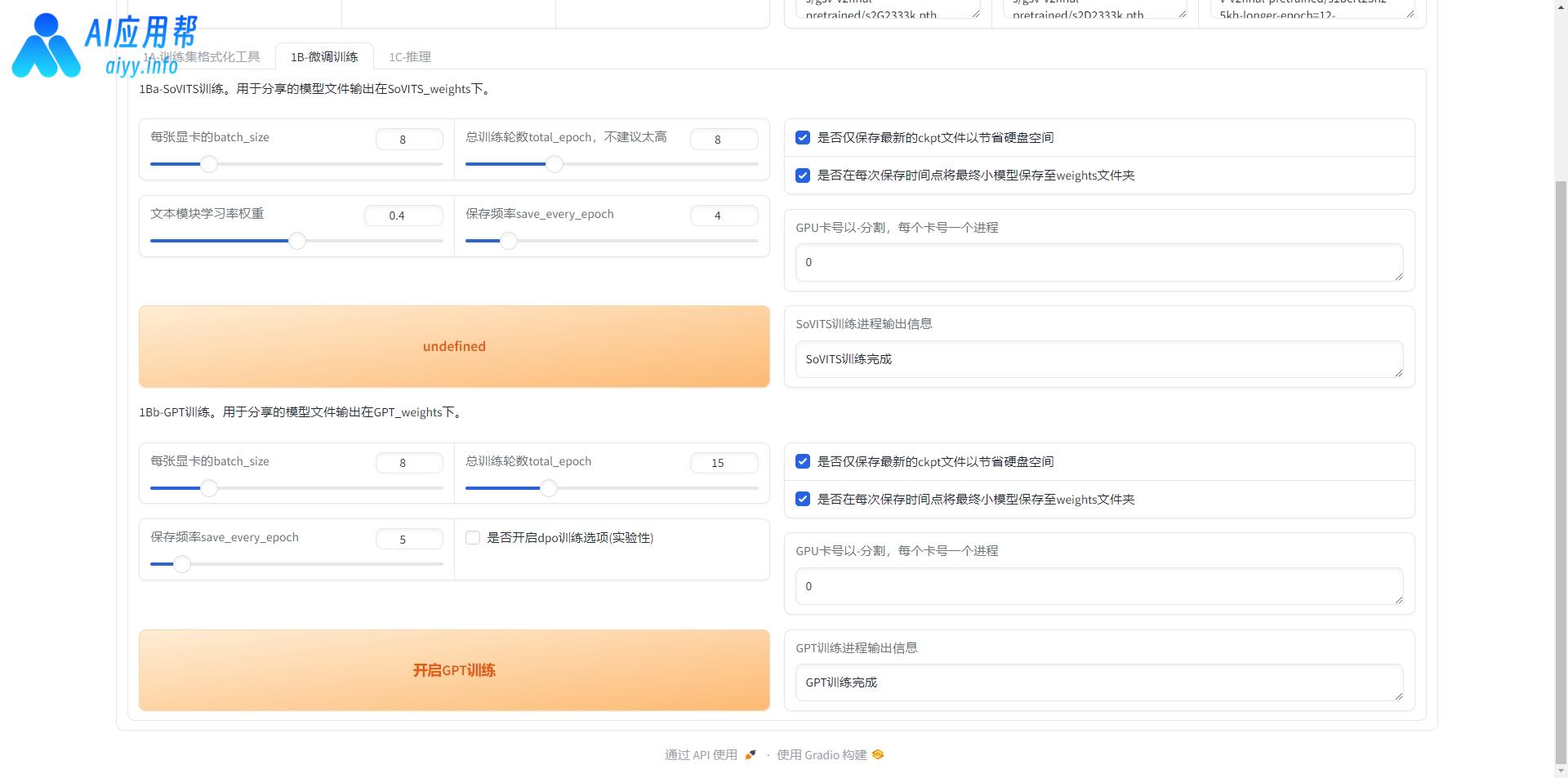
点击“1B-微调训练”切换到微调界面,先点击“开启SoVITS”训练,等到右侧输出信息提示“训练完成”之后,再点击“开启GPT训练”,等到右侧输出信息提示“训练完成”之后开始下一步推理。
⑤ 生成音频
1、推理:就是输入文本合成音频。
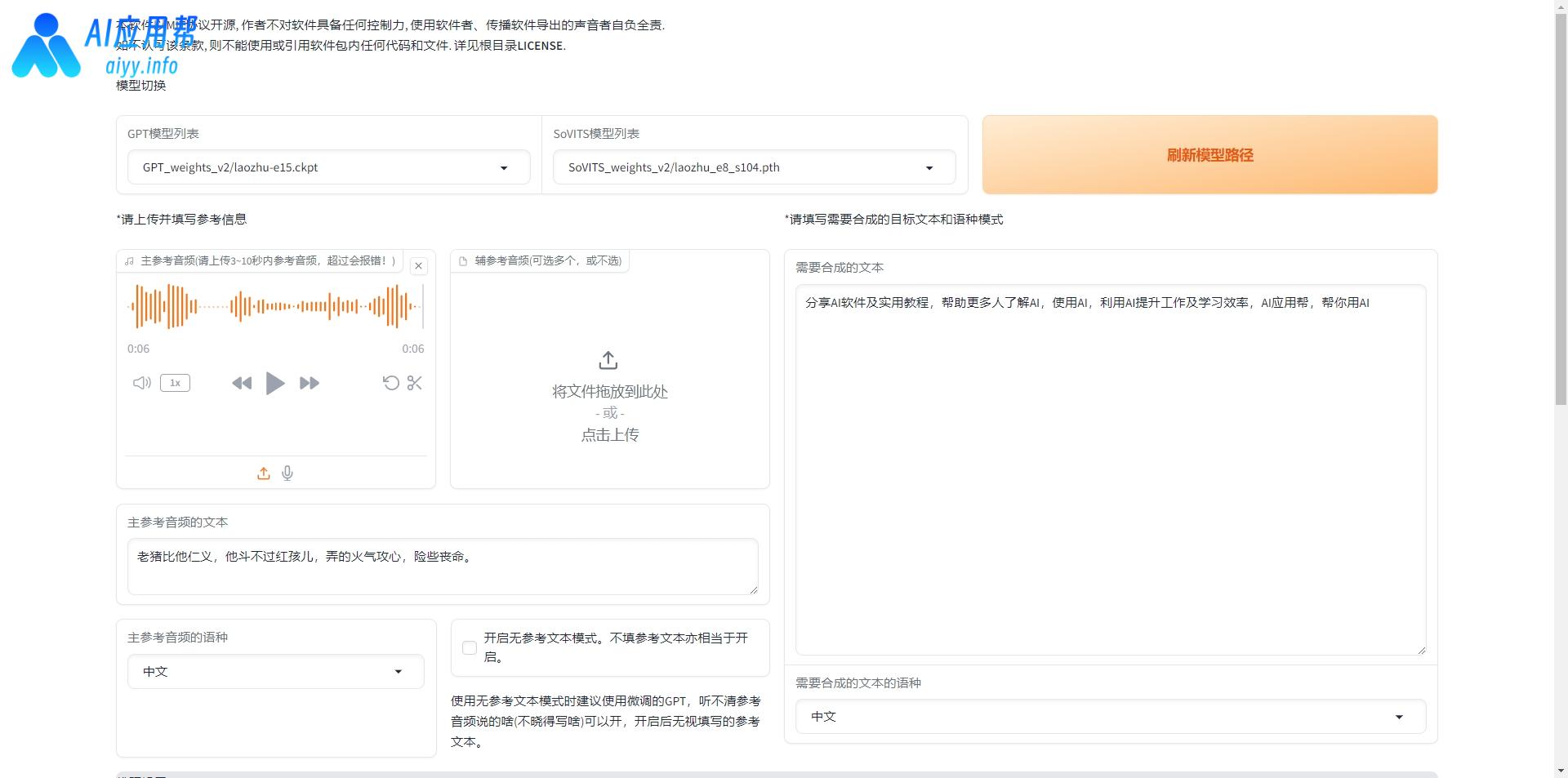
点击“1C-推理”切换到推理界面,点击“刷新模型路径”,然后分别选择刚训练好的GPT模型和SoVITS模型(模型名字就是前面的环节取的名字,选数值高的那个),可以勾选并行推理,然后点击“开启TTS推理WebUI”。
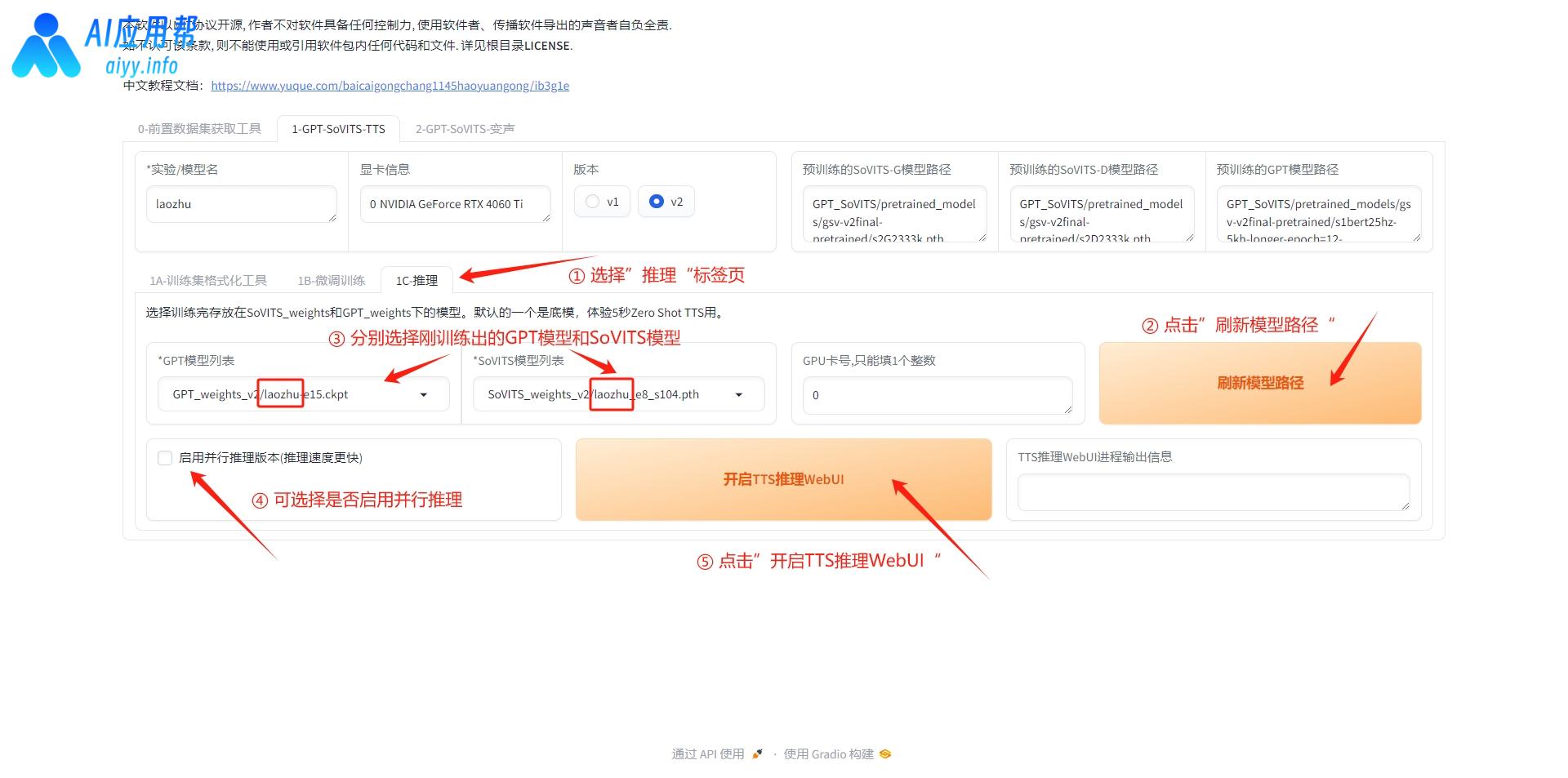
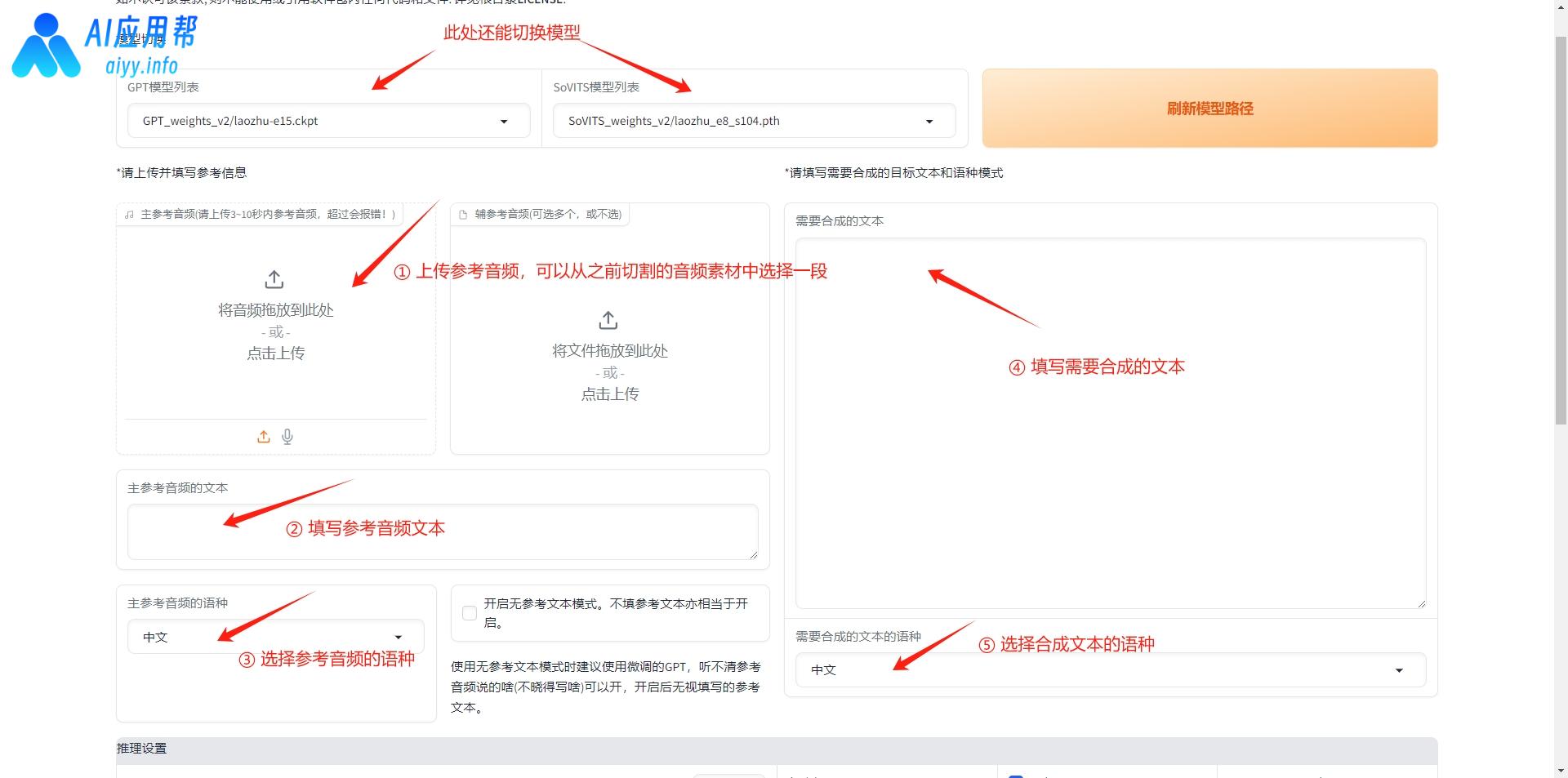
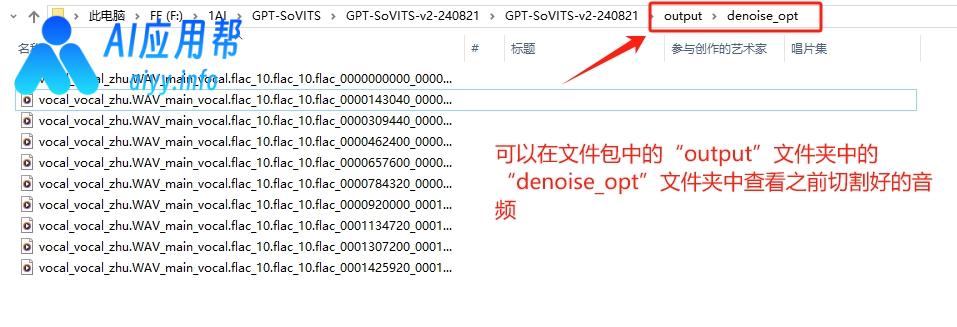
开始合成音频之前还需要上传一段3-10秒参考音频的素材,以优化生成效果,这个素材可以选择之前切割好的音频文件,在文件包中的“output”文件夹中的“denoise_opt”文件夹可以查看之前切割好的音频文件,选择其中一段上传,并填写对应的文本,然后选择参考音频的语种,再填入需要合成的文本,选择合成文本的语种,最后下滑点击“合成语音”即可。
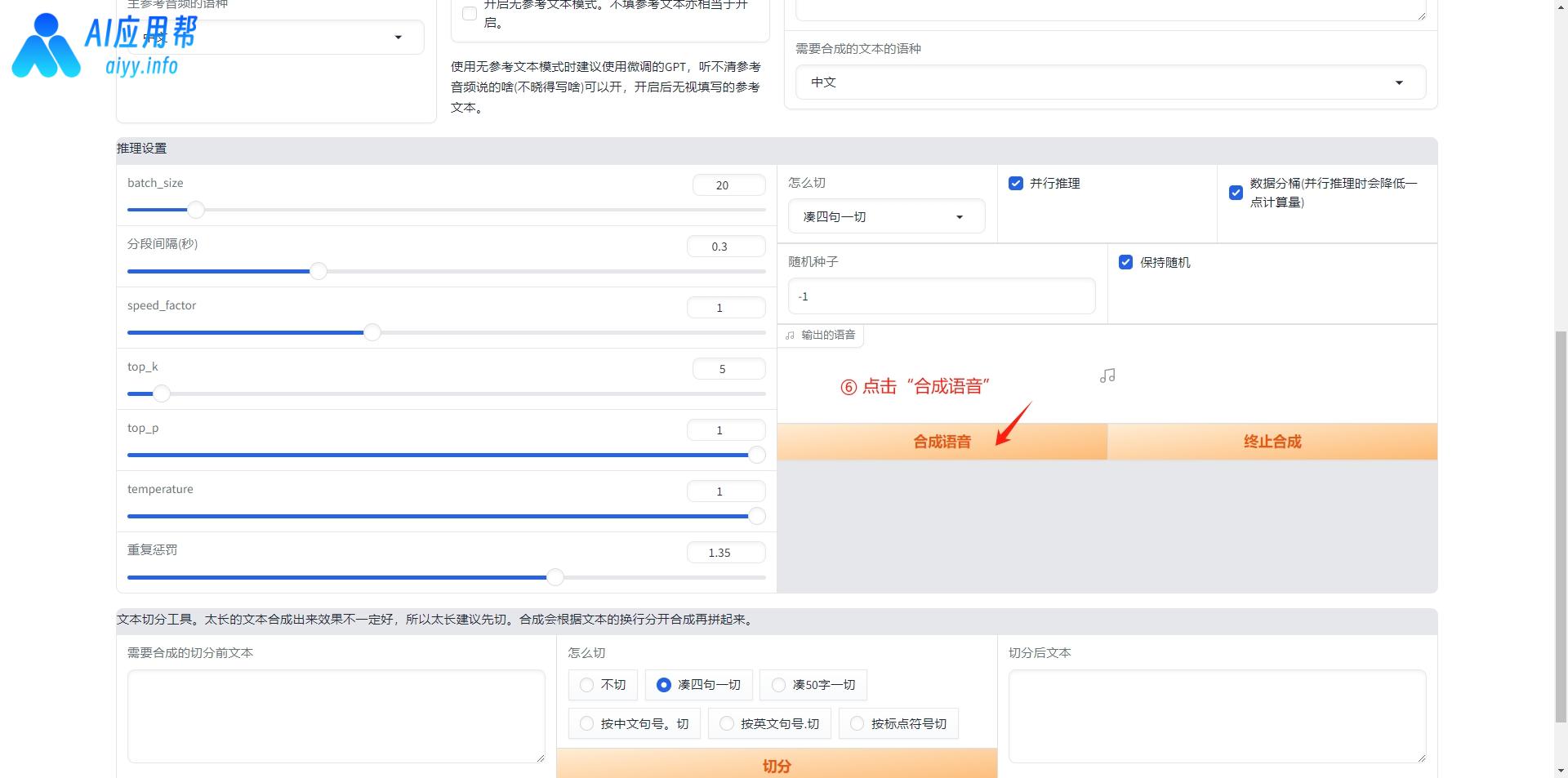
如果是长文本,建议将文本进行切分,在界面底部有切分工具,将长文本粘贴进去,选择切分方式,然后点击“切分”,右侧框会生成切分好的文本,将其复制下来,粘贴到“需要合成的文本”框中,再点击“合成语音”即可。

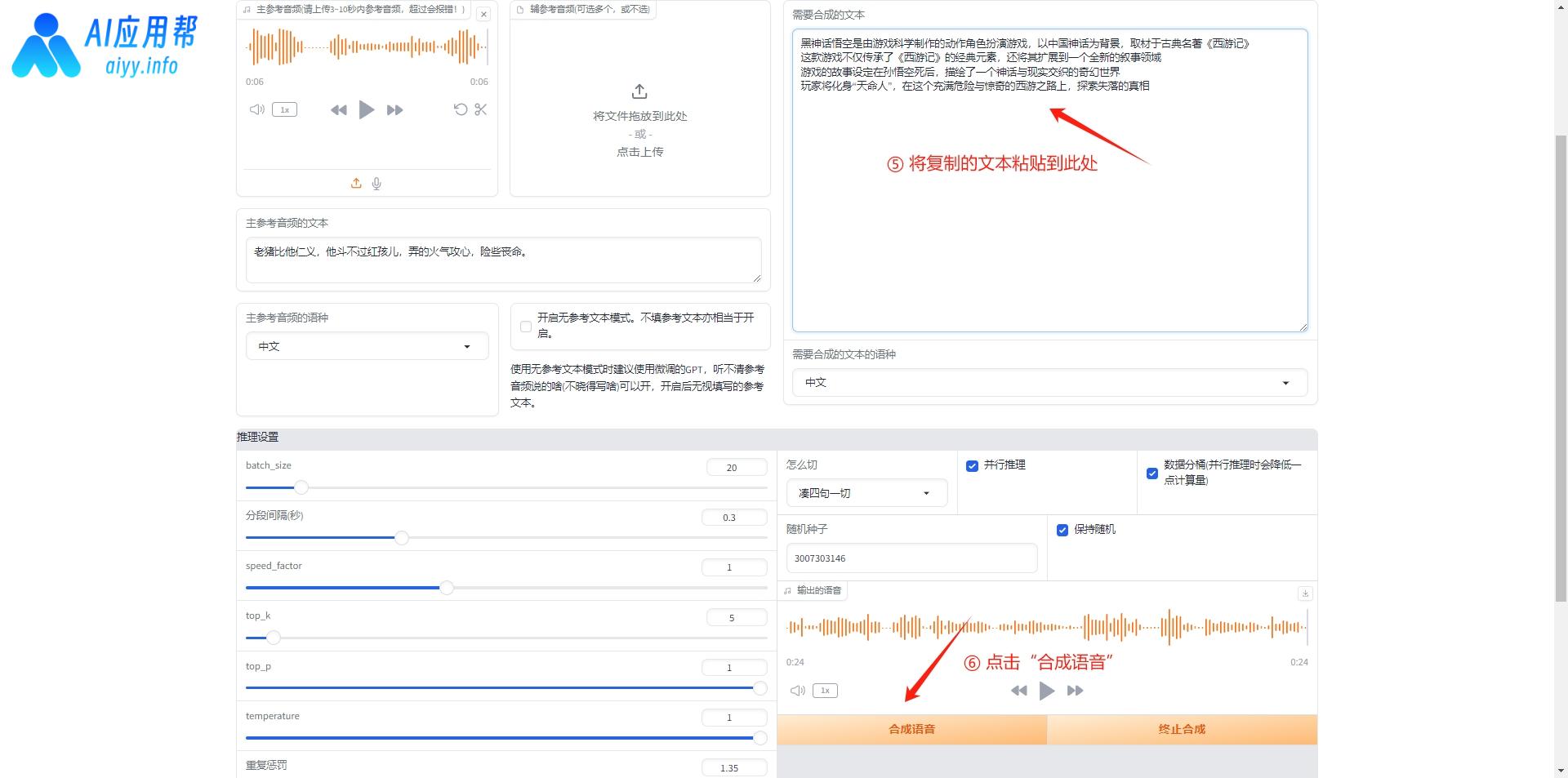
合成结果在“合成语音”按钮上方,点击播放按钮可以试听,点击下载按钮可以保存至指定文件夹。


