

Qwen2-VL 是阿里通义千问发布的第二代视觉语言模型,展现了在多模态任务中的领先优势,支持图片理解、视频分析等。
开源地址:https://github.com/QwenLM/Qwen2-VL
☞☞☞☞☞☞ 一键启动包在右侧下载 ☞☞☞☞☞☞
软件功能:
- 图像理解:Qwen2-VL 可以准确解析不同分辨率和长宽比的图片,在多个视觉语言任务中表现出色,如MathVista、DocVQA、RealWorldQA、MTVQA等基准测试。
- 视频理解:支持对20分钟以上的长视频进行理解,并能基于视频内容进行问答、对话和内容创作。
- 多语言文本理解:能够识别和理解图像与视频中的多语言文本,包括中文、英文、大多数欧洲语言、日语、韩语、阿拉伯语和越南语等。
- 多模态模型领先表现:在多个权威测评中,Qwen2-VL 刷新了多模态模型的最佳成绩,部分指标超越了 GPT-4o 和 Claude3.5-Sonnet 等闭源模型。
应用场景:
- 视觉识别和问答系统:适用于各种需要视觉和语言联合处理的应用,如智能问答系统、图像搜索引擎等。
- 视频分析与创作:用于理解和生成基于视频内容的创作,如视频剪辑、内容分析和自动生成解说等。
- 多语言文本处理:适用于需要处理多语言文本的场景,如跨语言翻译、全球化内容创作等。
配置要求:
建议电脑满足以下配置:
- 操作系统:Windows 10/11 64位
- 显卡:至少8G显存的英伟达(NVIDIA)显卡,图片理解对显存占用较低,但视频分析对显存要求较高,个人显卡能支持的视频长度比较有限
- CUDA= 12.5
CUDA如未安装可以查看安装教程:https://aiyy.info/requirements/
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小

使用教程:
① 打开下载页面(https://aiyy.info/qwen2-vl/)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件下载地址:https://www.winrar.com.cn/)
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

② 双击“一键启动.exe”,稍等片刻会在浏览器中自动打开操作界面

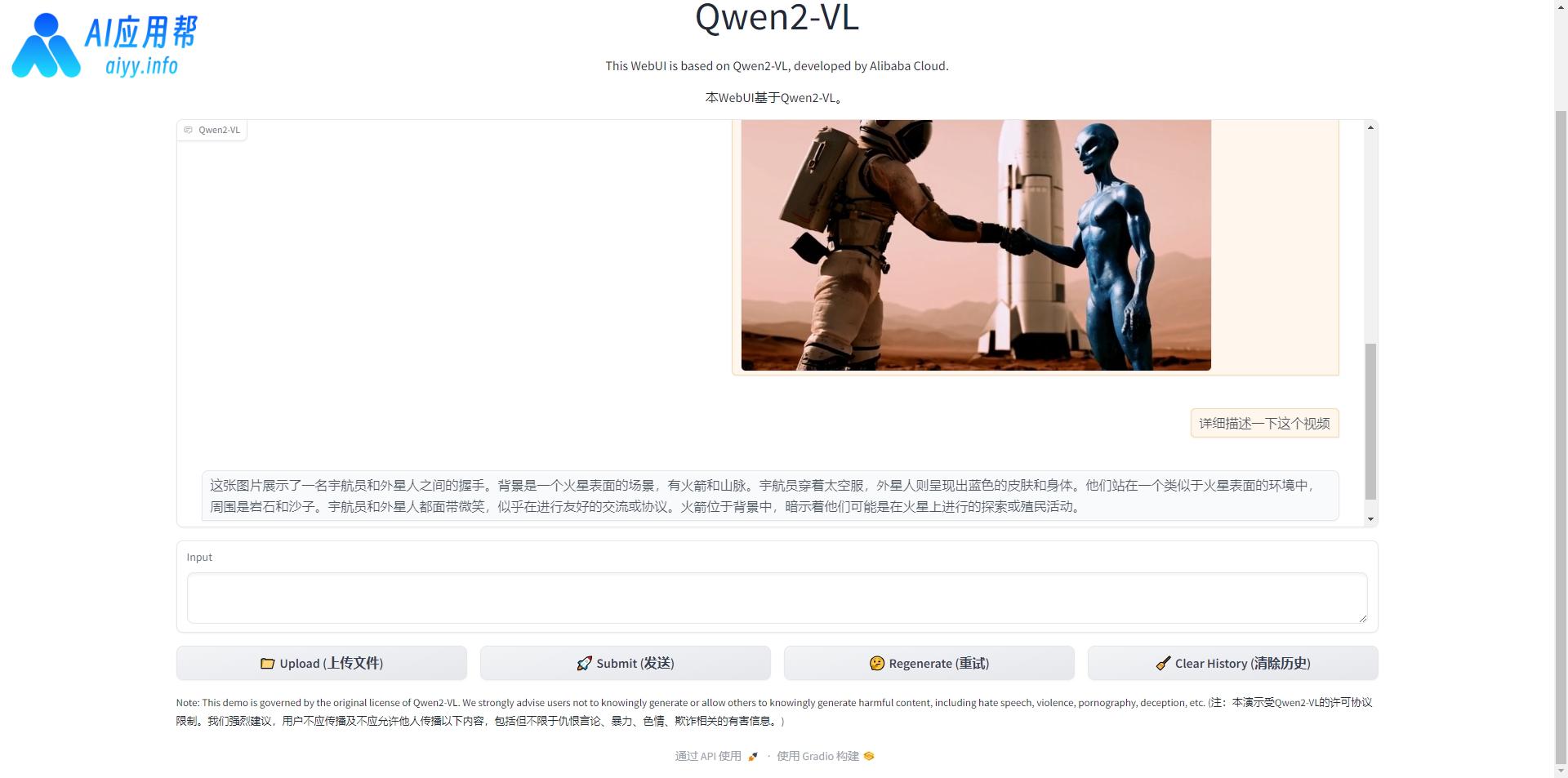
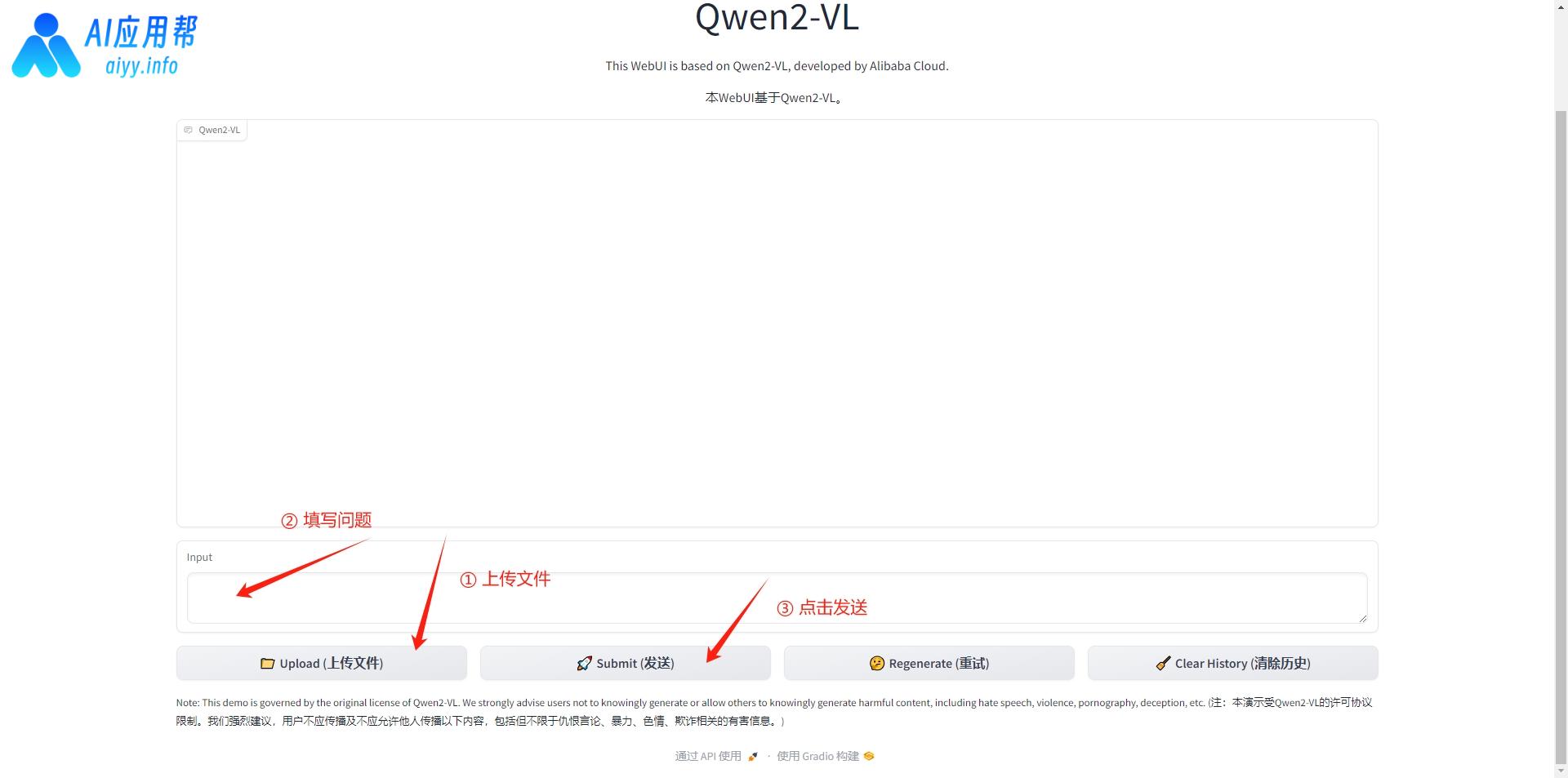
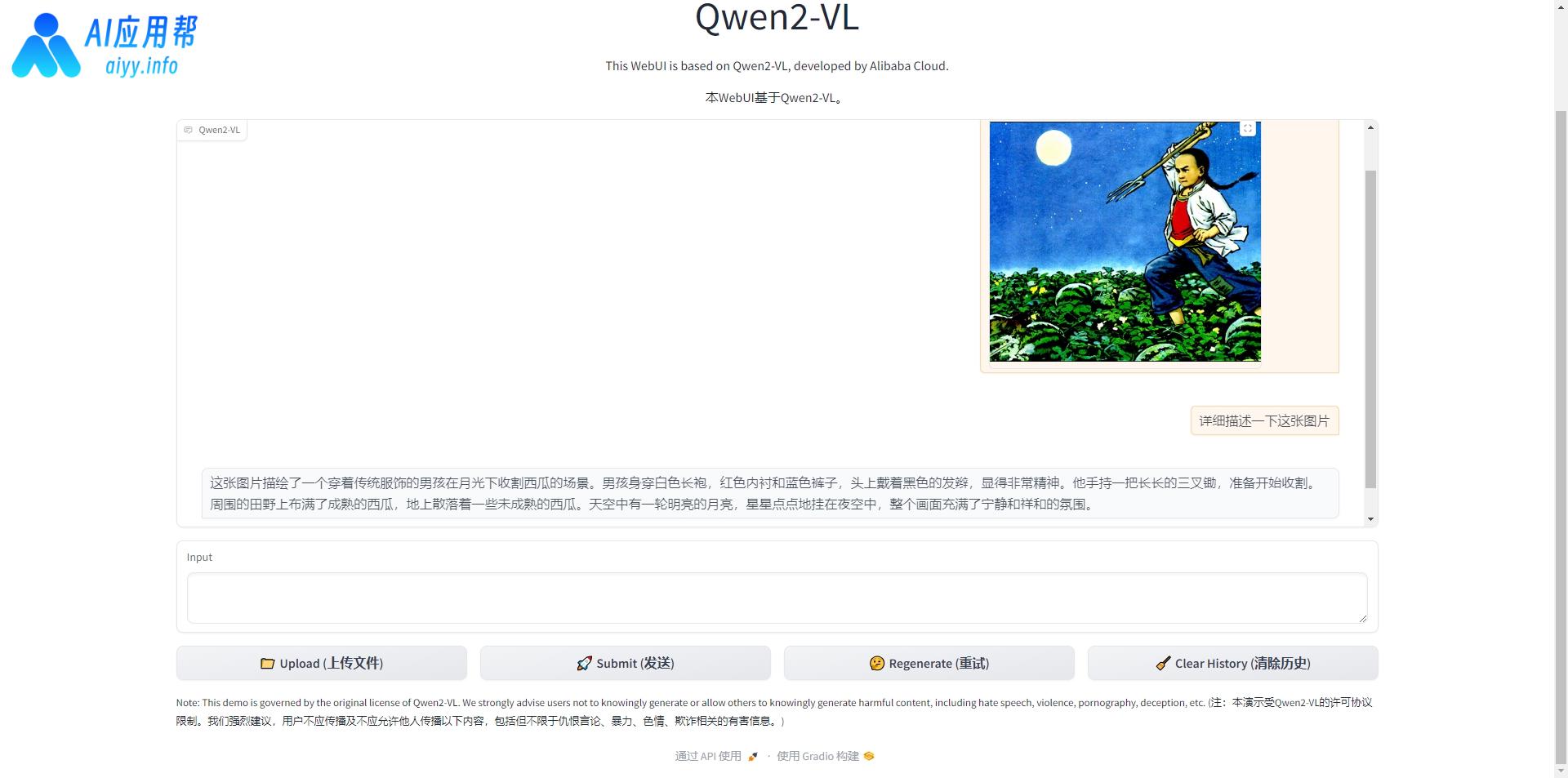
③ 先上传图片或视频文件(视频分析对显存要求较高,个人显卡能支持的视频长度比较有限,不建议上传长视频,容易超显存导致报错),然后填写问题,再点击发送,等待模型回复即可
声明:
① 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考赞助计划。
② 本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

