
请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载

Seed-VC 是一款AI 声音转换工具,能让用户瞬间模仿指定的声音,具有极高的娱乐性和创作潜力。效果感觉不如RVC,但胜在简单,不用训练模型。
2025.4.16:更新V2版本模型
开源地址:https://github.com/Plachtaa/seed-vc
☞☞☞☞☞☞ 右侧下载整合包 ☞☞☞☞☞☞
配置要求:
电脑需满足以下配置:
- 操作系统:Windows 10/11 64位
- 内存:20G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡,显卡性能越好,生成速度越快
- CUDA:显卡支持的CUDA版本大于等于12.8版本(如不知道显卡支持的CUDA版本,可点击此链接查看:https://aiyy.info/supported-cuda-versions/)
- 整个包解压完约10.8G,要留足硬盘空间
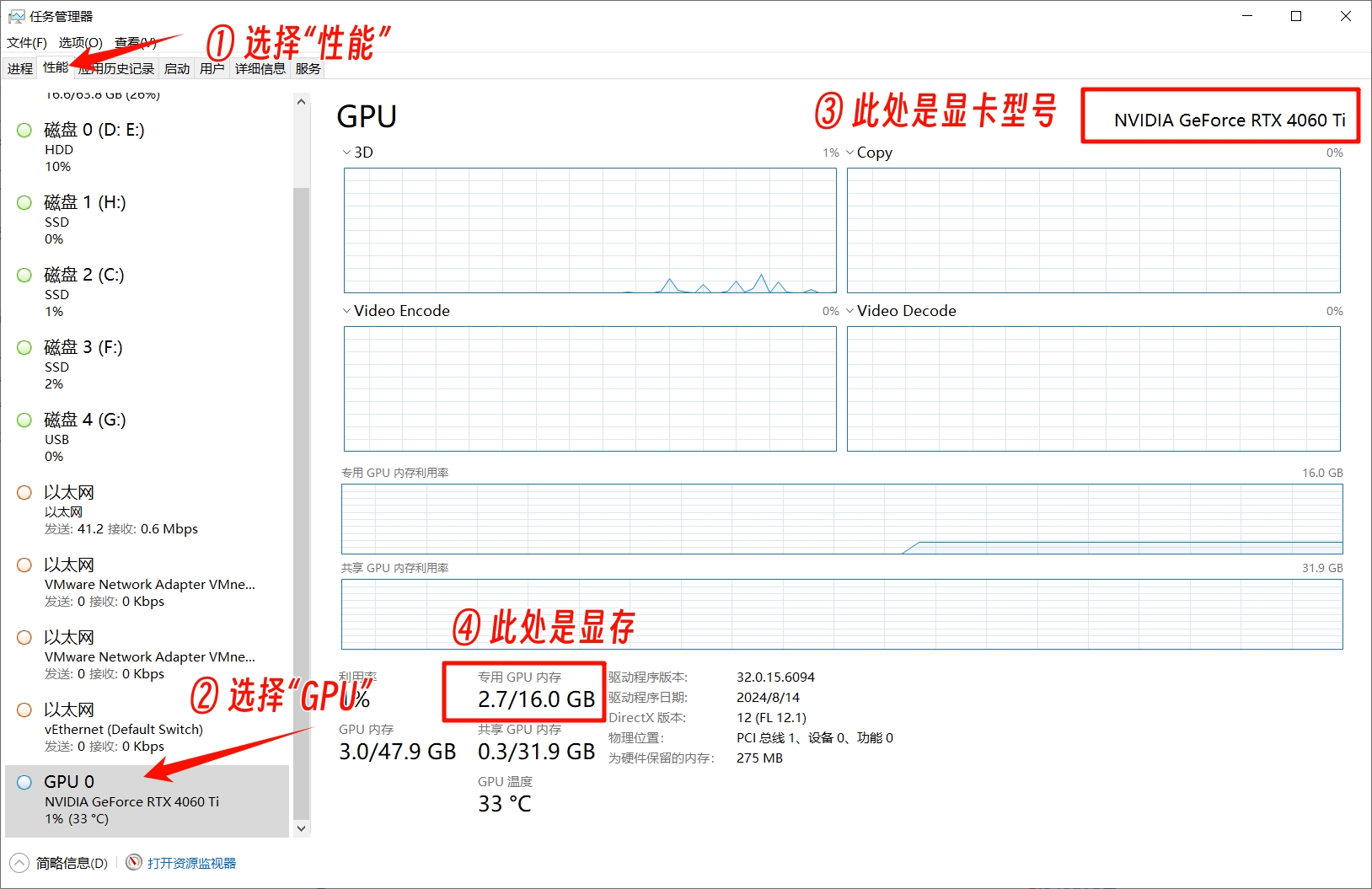
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
① 打开下载页面(https://aiyy.info/seed-vc/)点击页面右侧下载按钮,
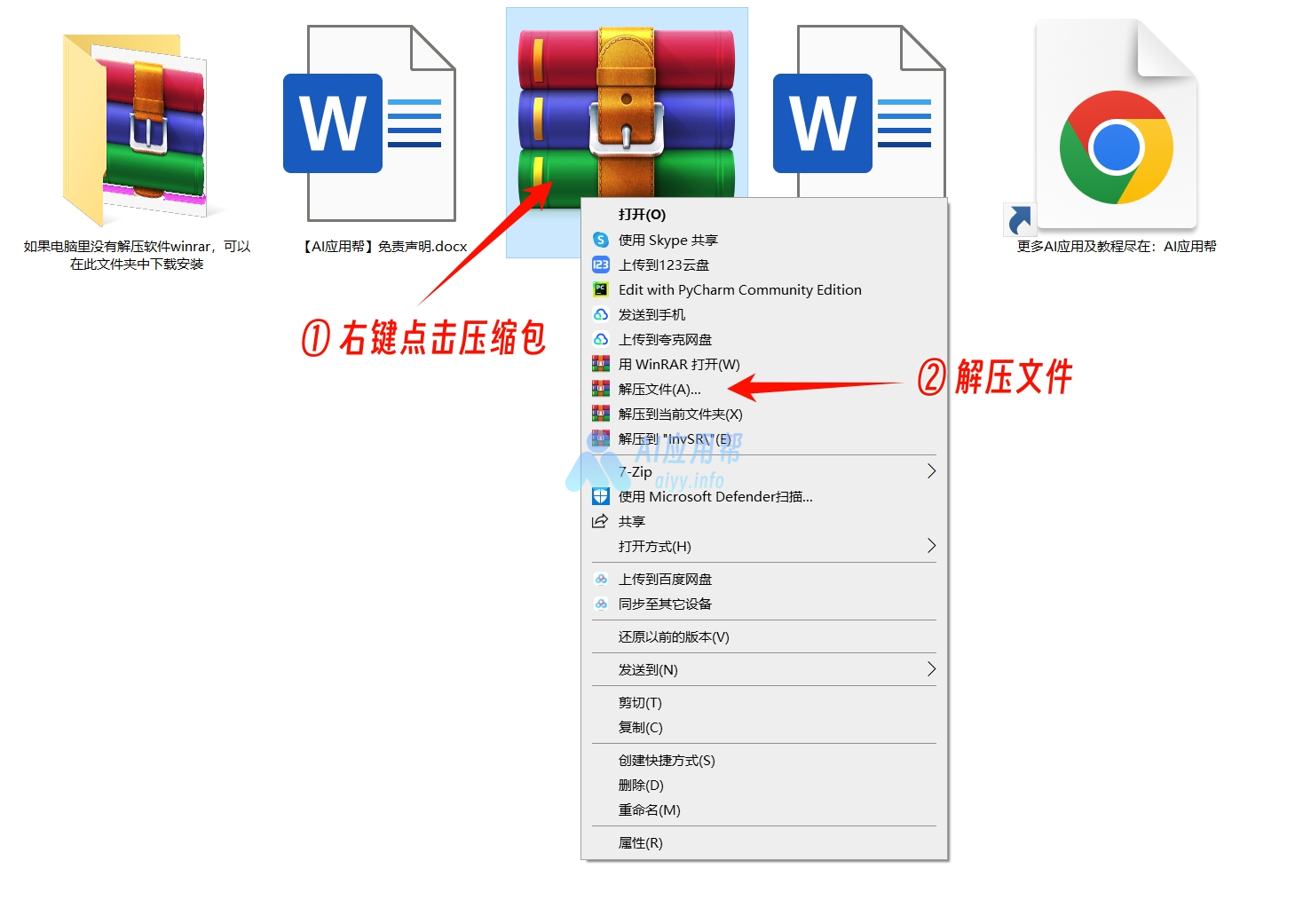
下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

V2版本使用教程:
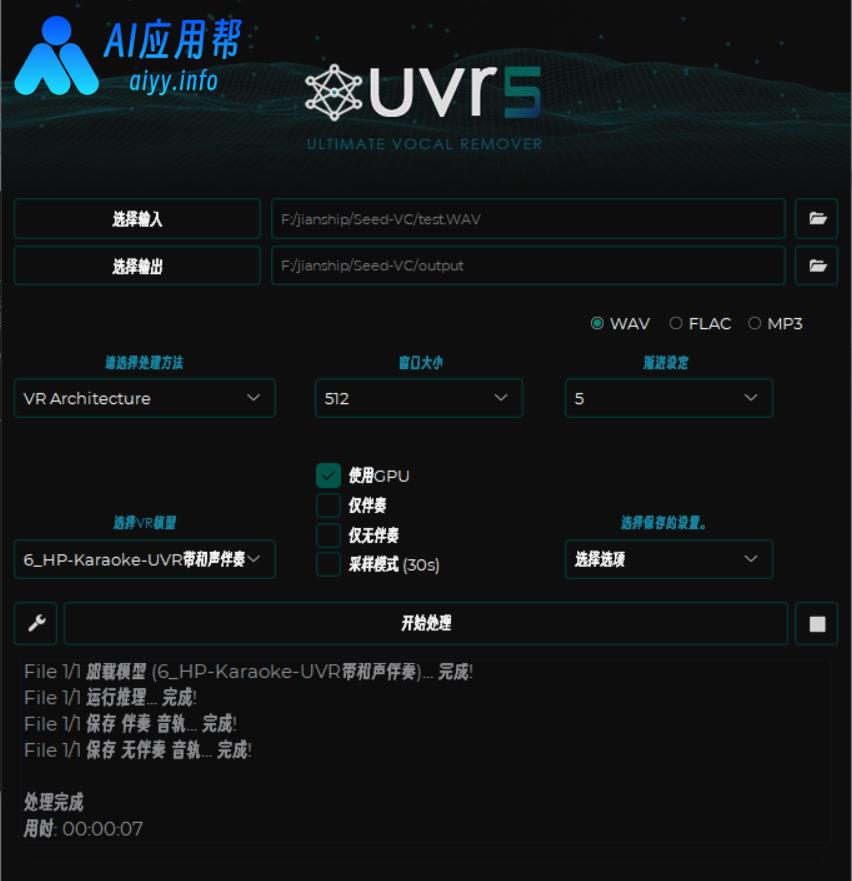
先处理音频,素材声音建议为干声(无背景音、无杂音),效果较佳,如果音频有背景音或者伴奏可以先用UVR处理一下
UVR使用教程及下载链接:https://aiyy.info/uvr5/
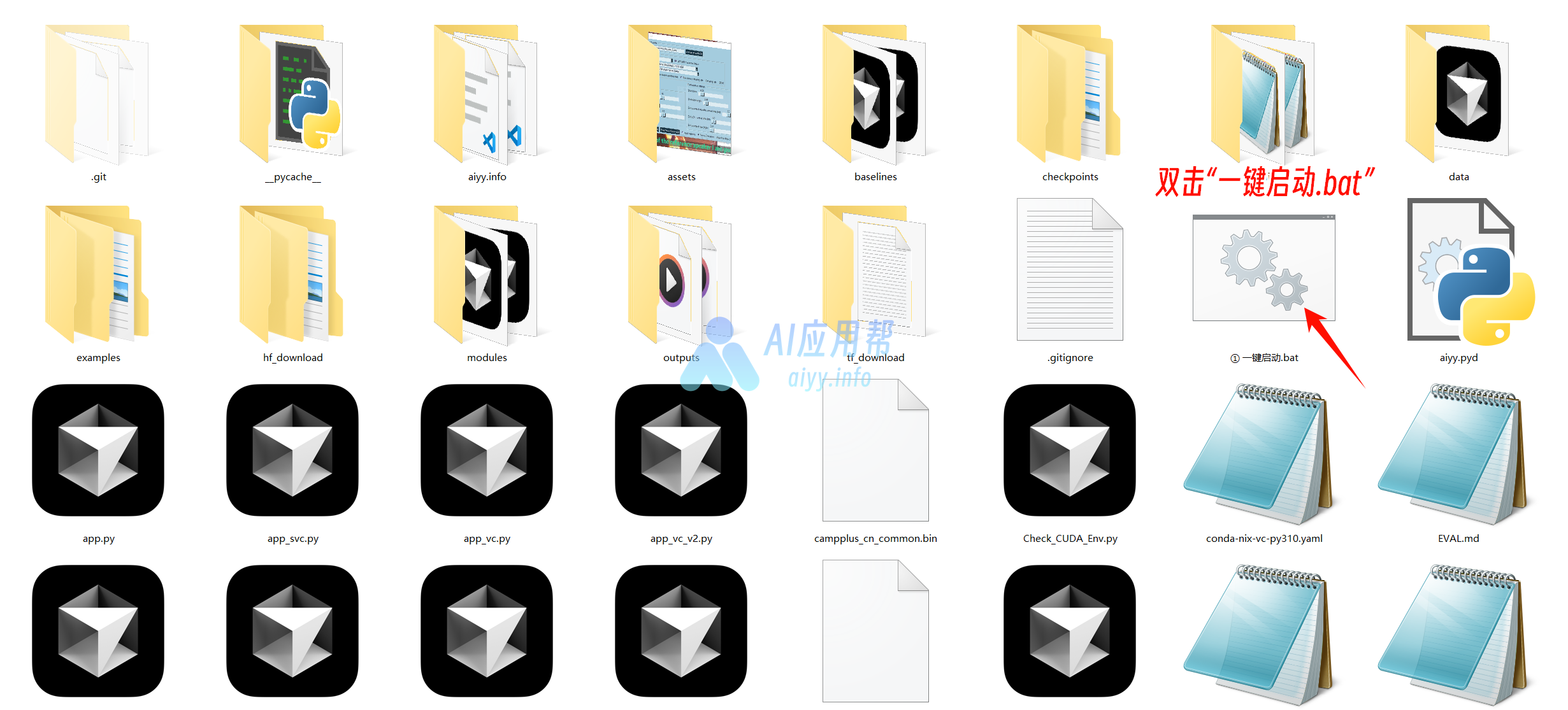
② 双击“一键启动.bat”,稍等片刻会在浏览器中自动打开操作界面
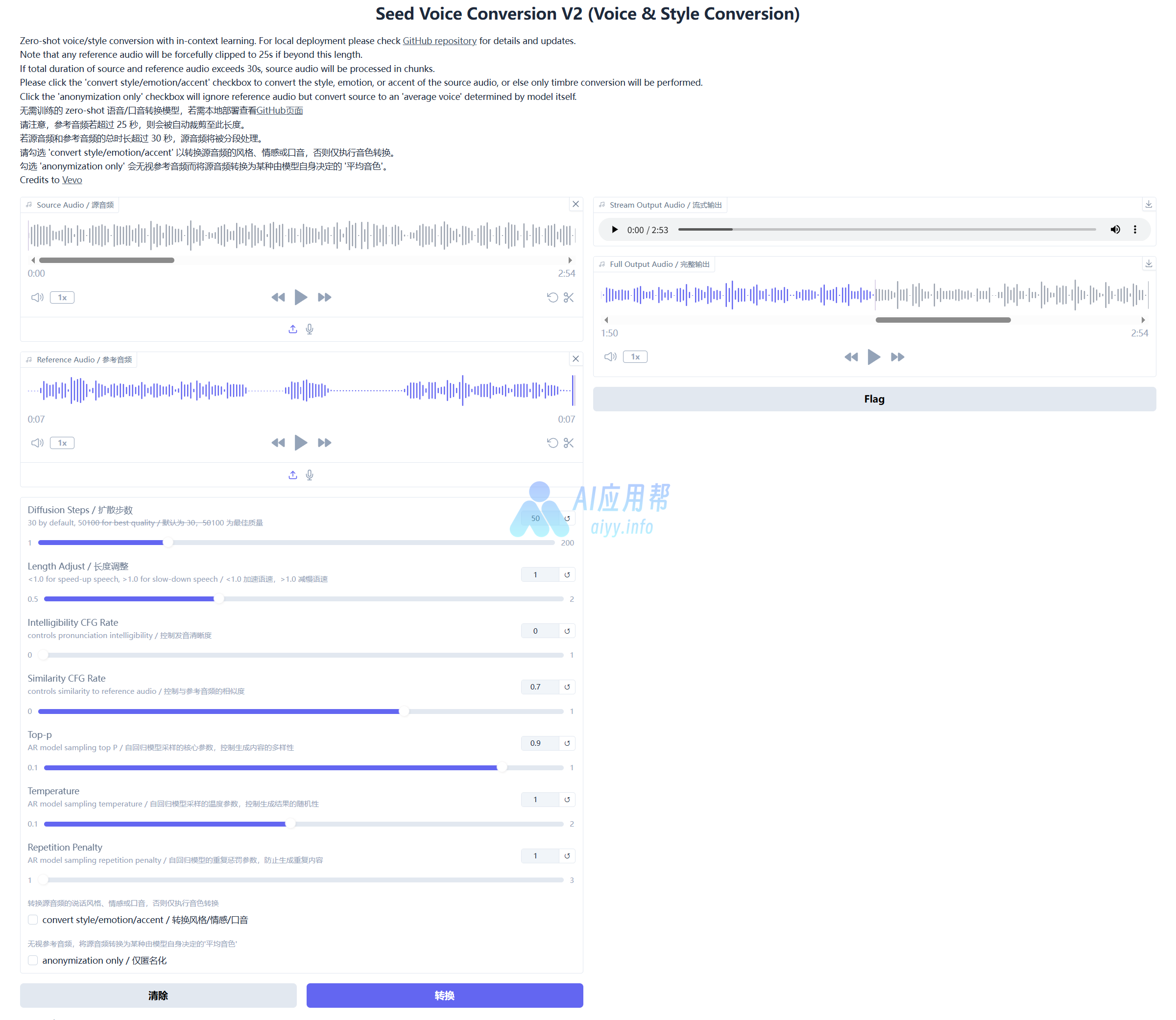
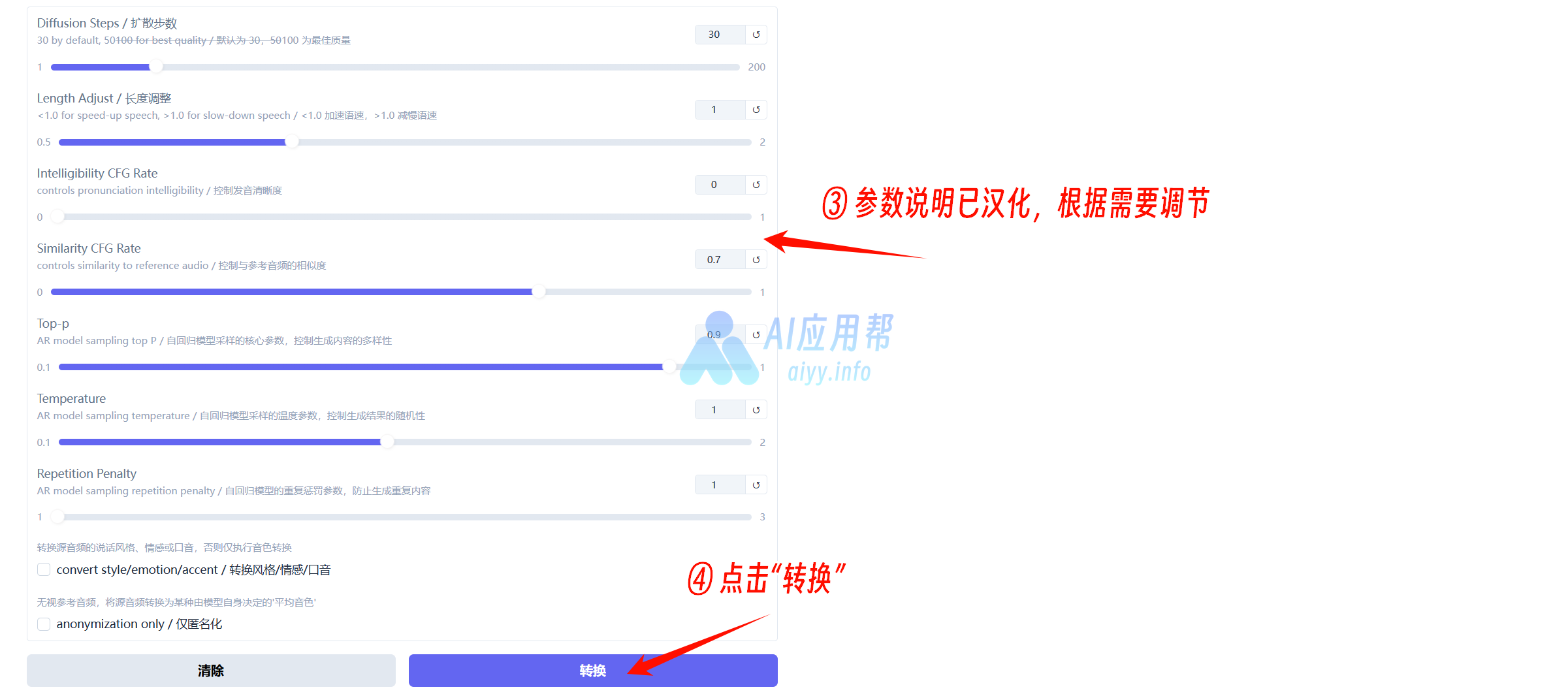
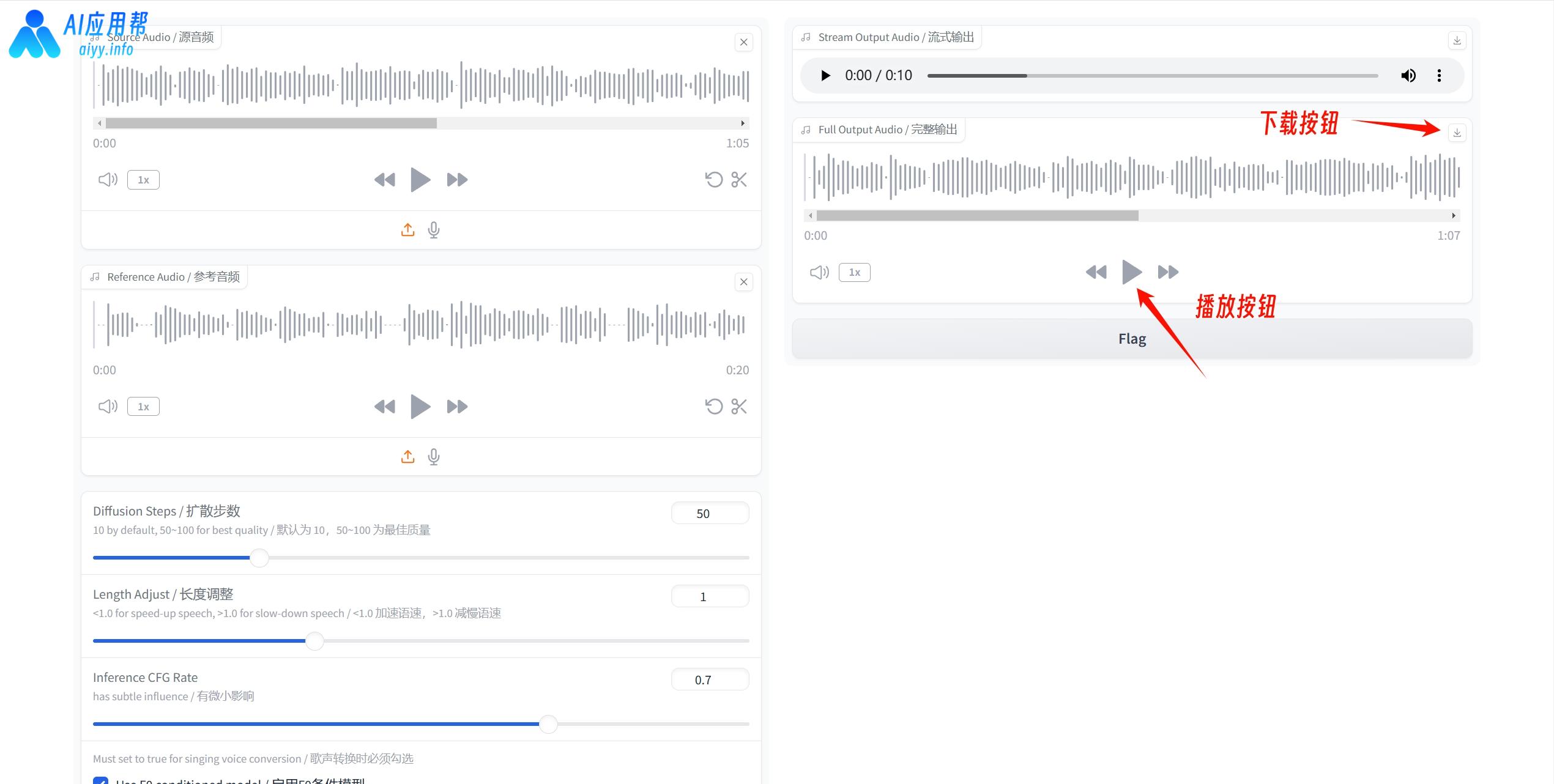
③ 上传源音频,再上传参考音频,根据需要调整参数,一般保持默认即可,最后点击“转换”
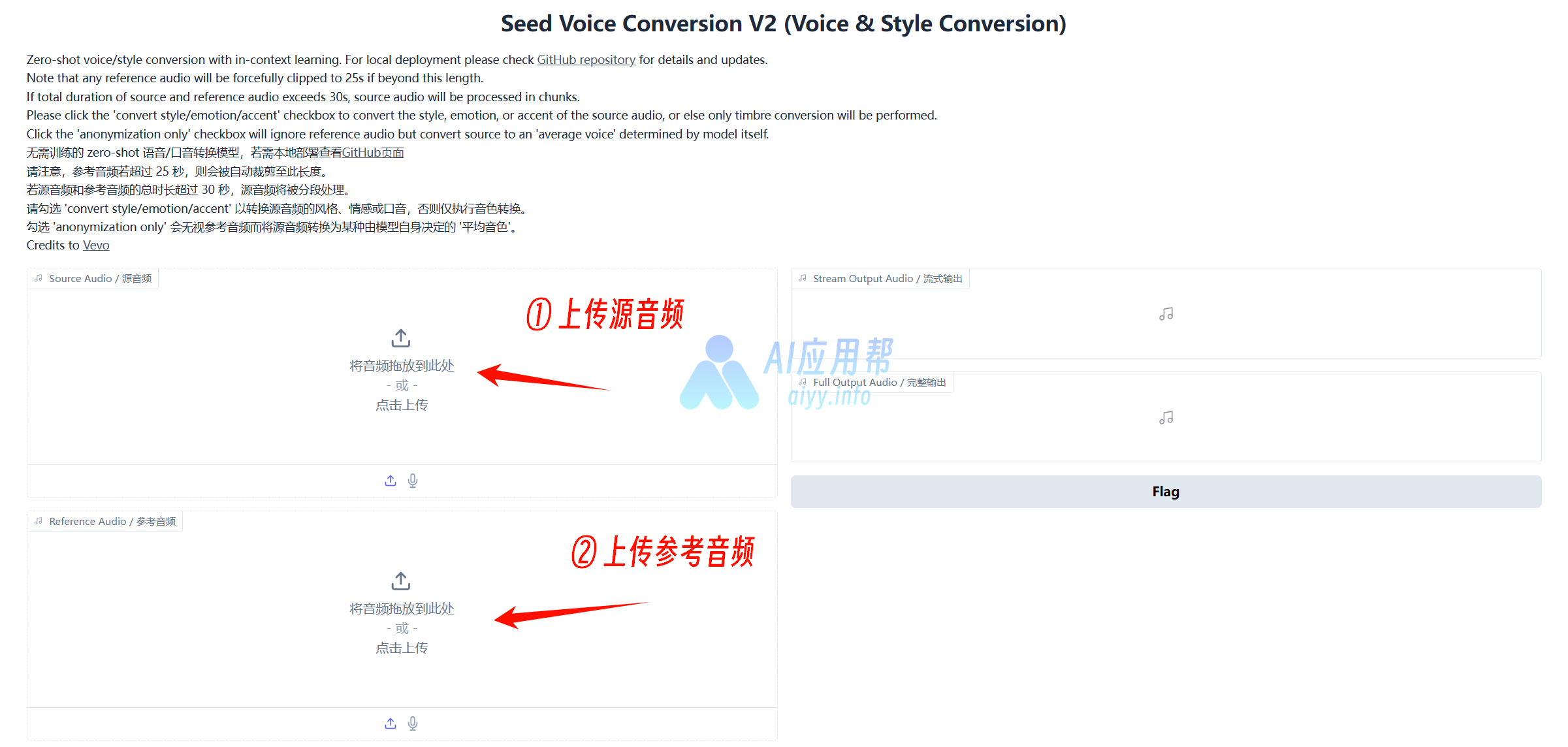
如下方所示
源音频:
参考音频
生成结果
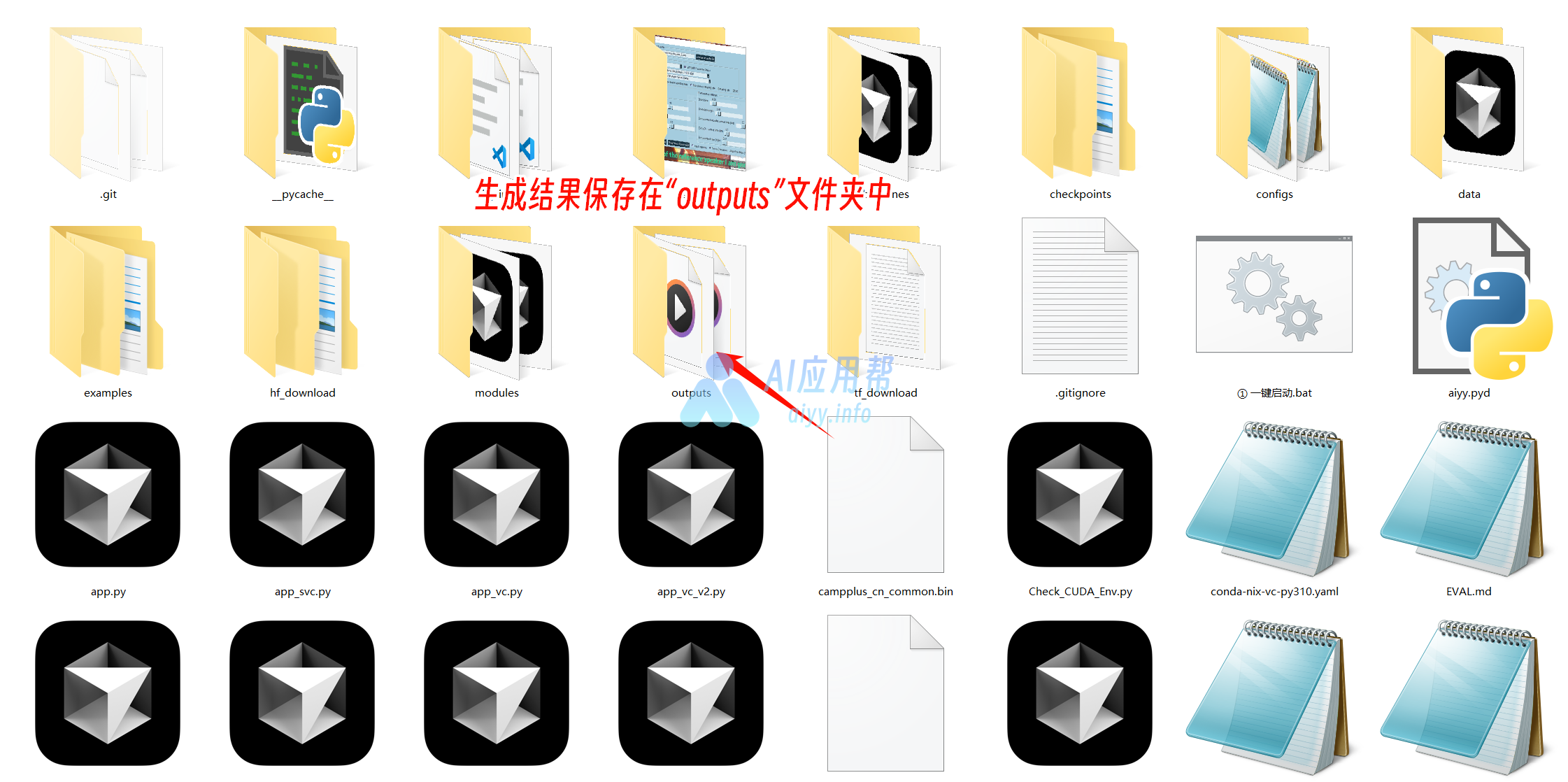
④ 生成结果保存在“outputs”文件夹中
V1版本使用教程:
② 首先一首歌曲素材,用UVR将人声和伴奏分离
UVR使用教程及下载链接:https://aiyy.info/uvr5/

原歌曲素材
分离后-人声
分离后-伴奏
人声中还有混响,也可以用UVR去除一下,效果会更好,这里简单演示,就仅做伴奏分离
③ 打开“Seed-VC”整合包,双击“一键启动.exe”,稍等片刻,会在浏览器自动打开操作界面
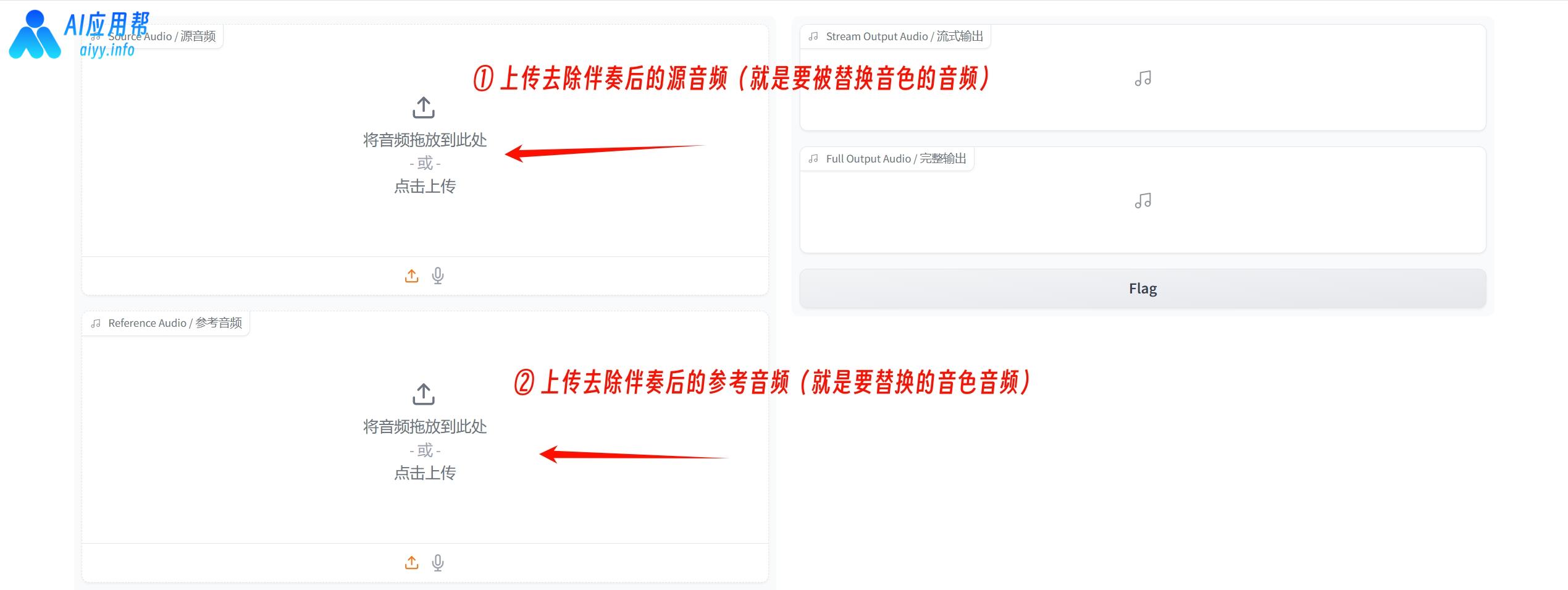
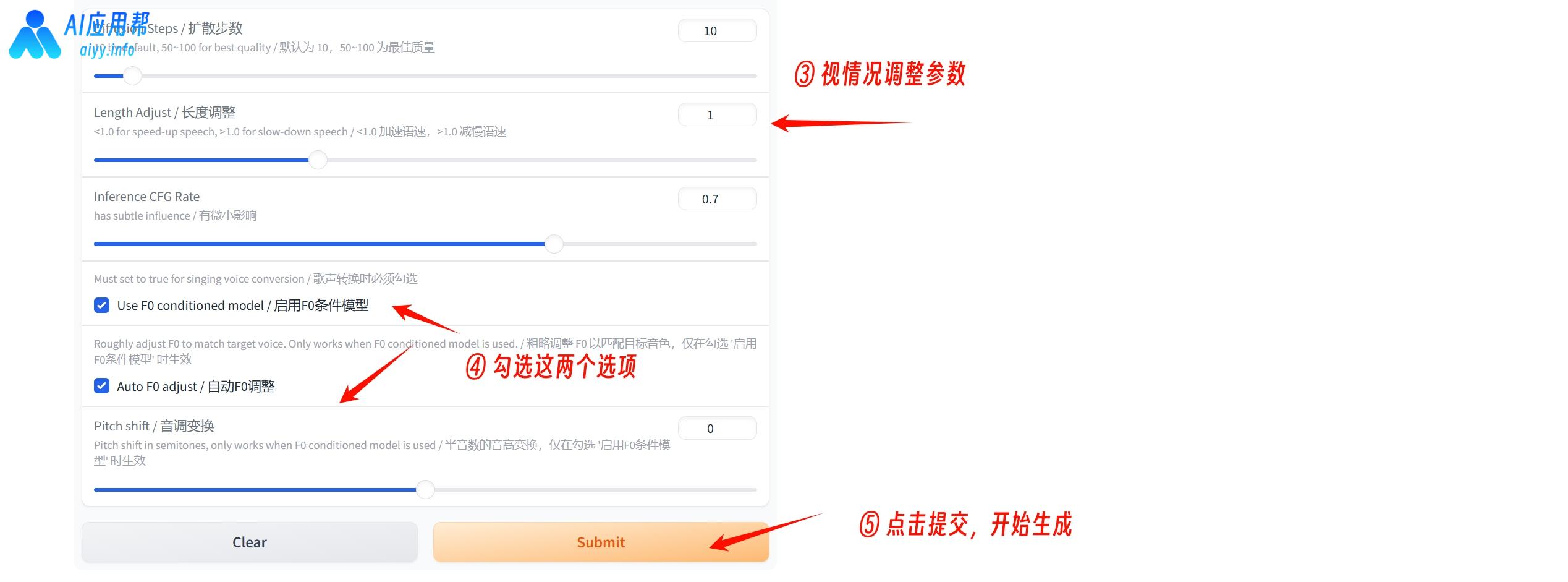
④ 在“源音频”框中上传去除伴奏后的歌曲源音频(就是要被替换音色的音频),再在“参考音频”框中上传去除伴奏后的参考音频(就是要替换的音色音频),参数视情况调整,一般调整“扩散步数”为50-100之间,再勾选“启用F0条件模型”以及“自动F0调整”两个选项即可,最后点击提交,即可开始生成
⑤ 生成结果位于右侧,可以点击播放按钮预览,点击下载按钮可以保存至指定文件夹
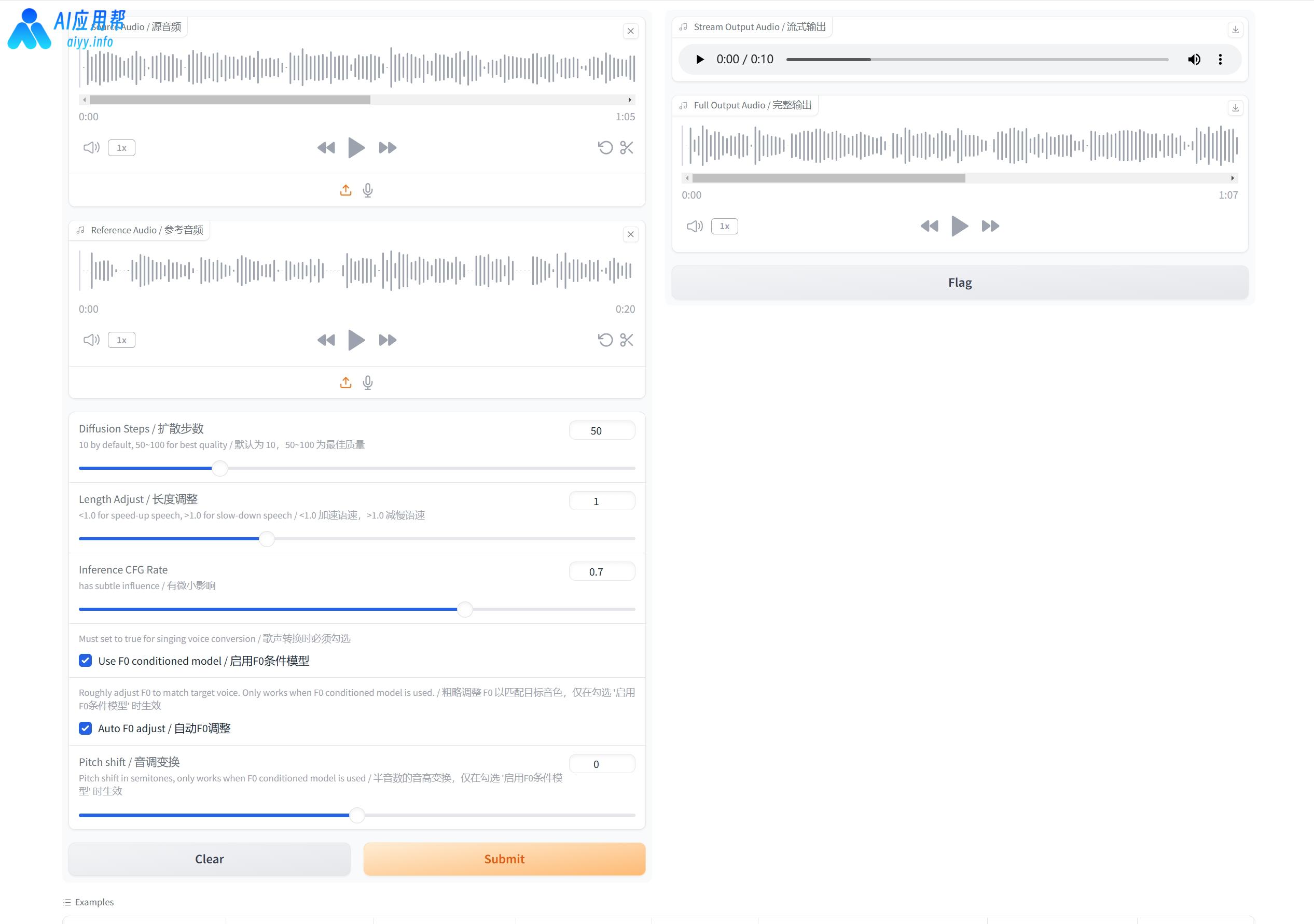
去除伴奏后的源音频
参考音频
生成结果
这里我用了说话的音色来替换了唱歌的音色,所以生成之后声音听起来比较平,不够饱满,可以用唱歌的声音替换唱歌的声音,效果会更好,参考音色建议音域比较广的,就是最好高低音都有的
⑥ 最后,用剪辑软件或者音频处理软件将生成后的结果和一开始分离出来的伴奏结合起来即可(这里用剪映作为示例)
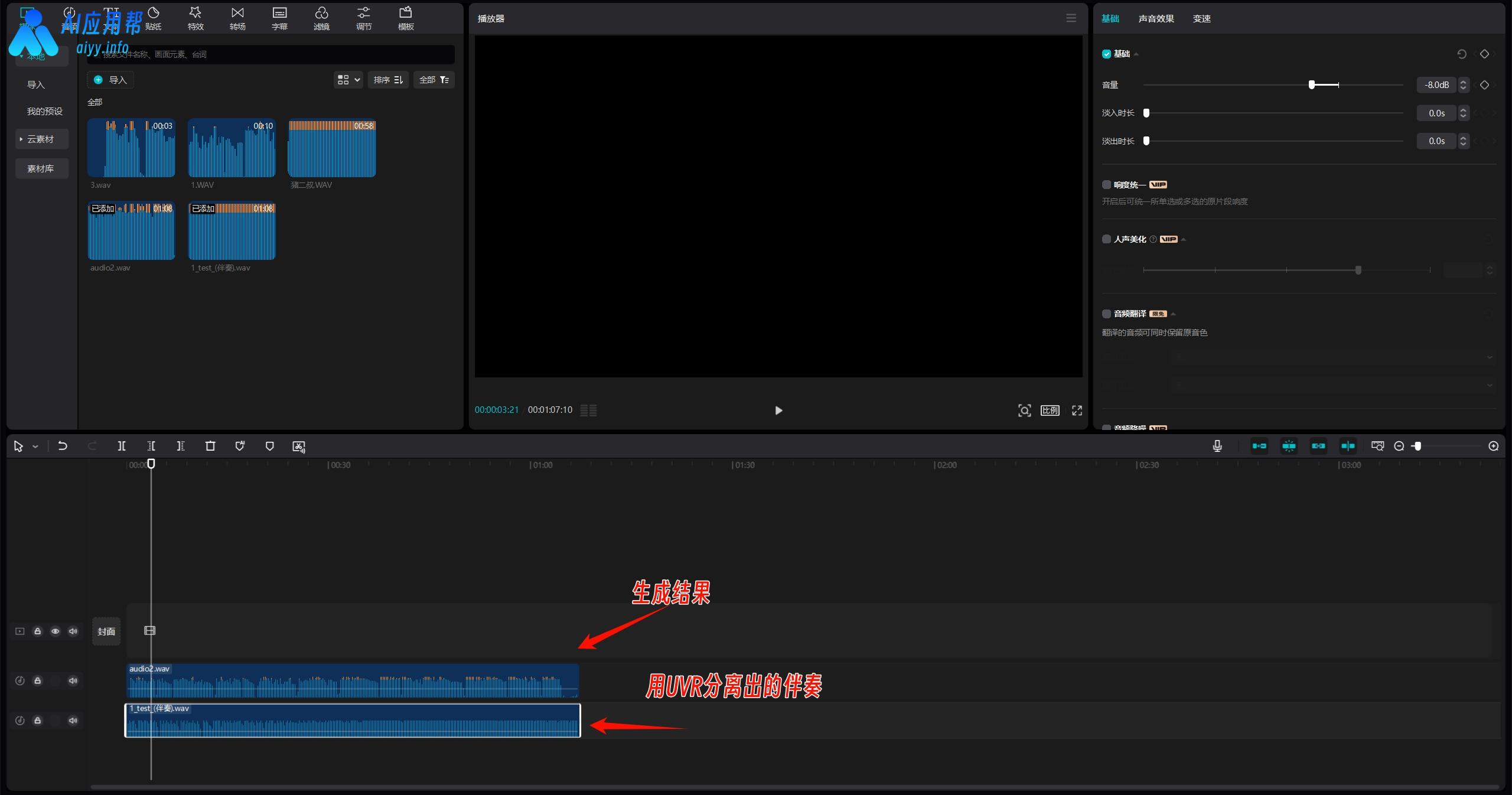
最终结果:
⑦ 除了唱歌,说话的声音也可以转换,操作步骤一致,就不再赘述了,下方是生成示例
源音频
参考音频
生成结果
补充内容:
如果启动出现下方报错,关闭启动窗口,重新启动即可,开了梯子的(就是科学上网工具)把梯子先关一下
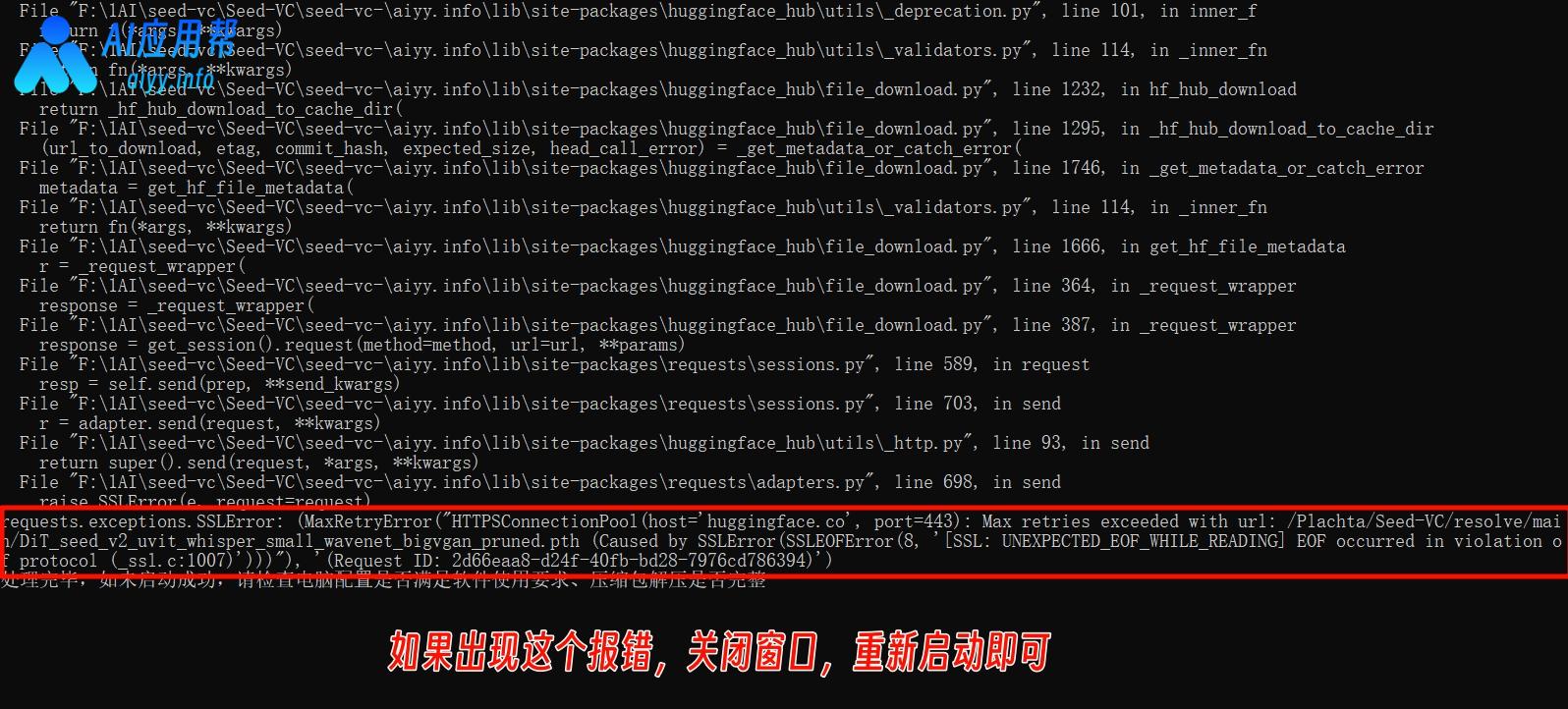
如果出现“LLVM ERROR: Symbol not found: __svml_cosf8_ha”报错
下载这个文件包,链接: https://pan.baidu.com/s/1_l292sATf-RrOMEZwCHhfw?pwd=aiyy
并将里面的 svml_dispmd.dll 粘贴到 C:\Windows\System32 文件夹中


