请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载

F5-TTS 是一款先进的文本转语音(TTS)系统,具备多语言切换、速度控制和情感表达等功能,为用户提供自然流畅的语音生成体验。其独特的零样本生成能力和大规模多语言训练,使其在多种场景下表现出色,尤其适合全球化背景下的交流需求。同时此版本还支持两人对话功能。
2025.4.17:更新v1_Base版本模型
开源地址:https://github.com/SWivid/F5-TTS
☞☞☞☞☞☞ 右侧下载整合包 ☞☞☞☞☞☞
软件功能
- 多语言切换:支持多种语言的文本转语音操作,能够在不同语言之间无缝切换,适应复杂的多语言输入。
- 零样本生成能力:该系统无需特定的训练样本即可生成高质量的语音,灵活应对新语言或未见过的语音风格。
- 语音速度控制:用户可根据需求调节语速,以适应不同场景的叙事节奏。
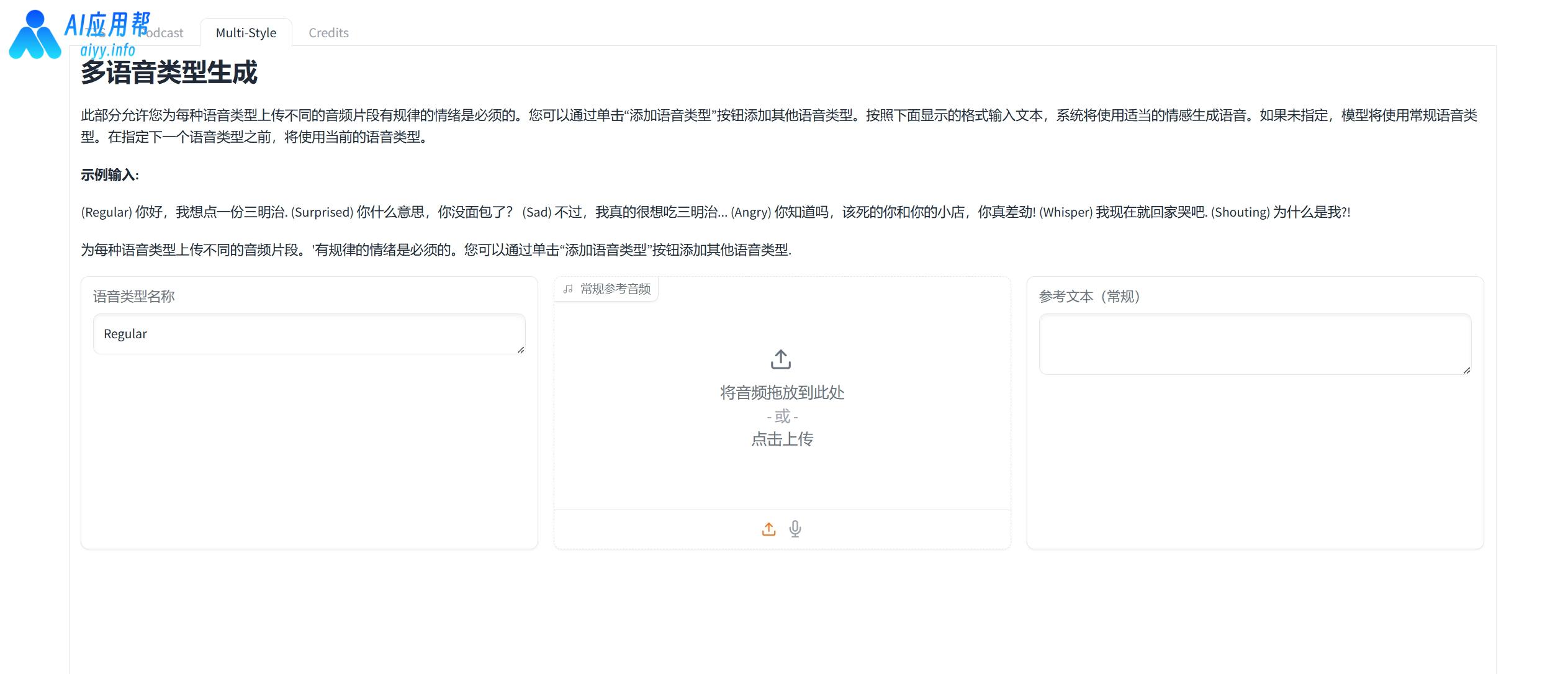
- 多人对话:支持设置两个角色对话。
配置要求:
电脑需满足以下配置:
- 操作系统:Windows 10/11 64位
- 内存:20G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡,显卡性能越好,生成速度越快
- CUDA:显卡支持的CUDA版本大于等于12.8版本(如不知道显卡支持的CUDA版本,可点击此链接查看:https://aiyy.info/supported-cuda-versions/)
- 整个包解压完约16.5G,要留足硬盘空间
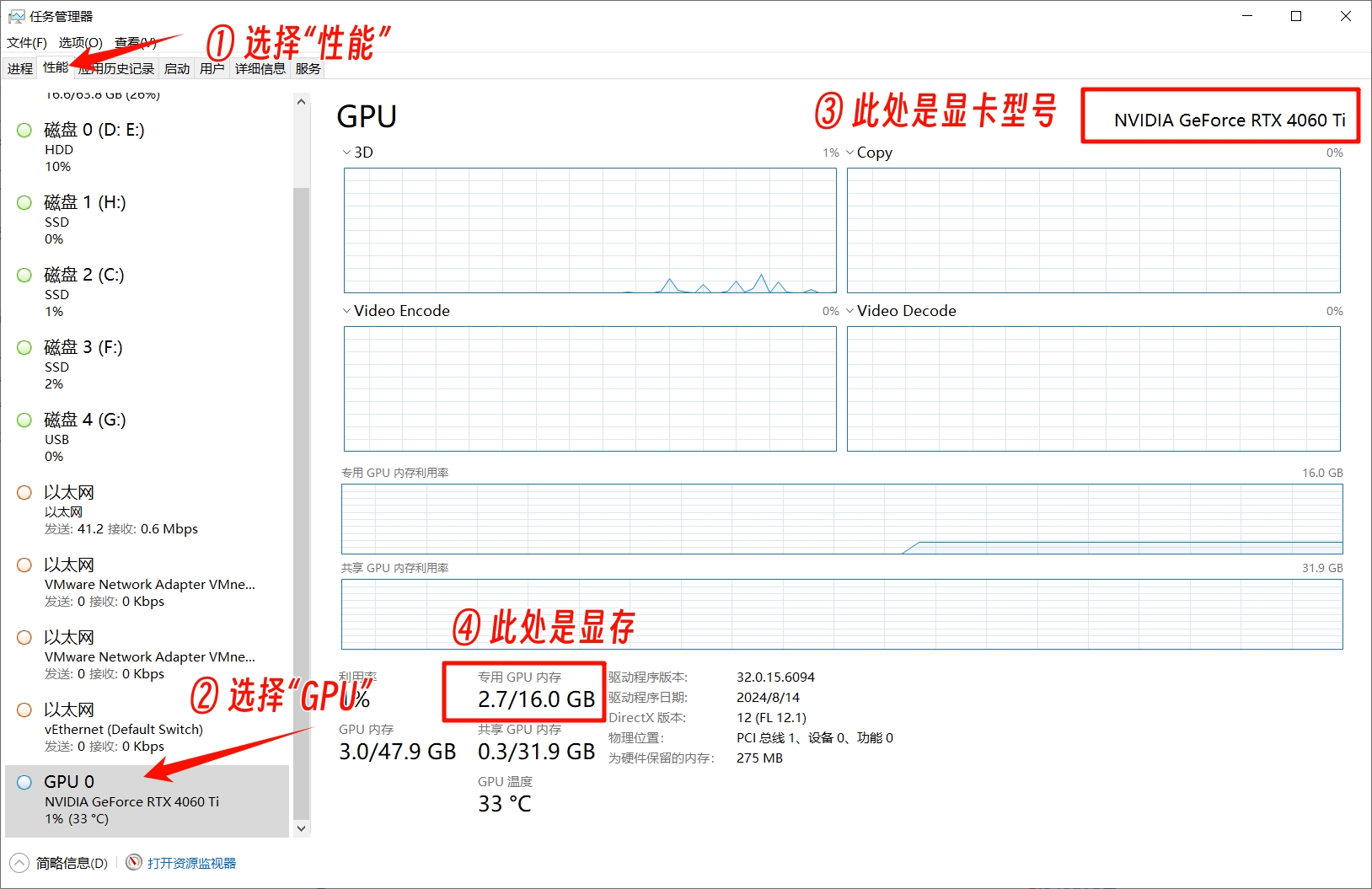
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
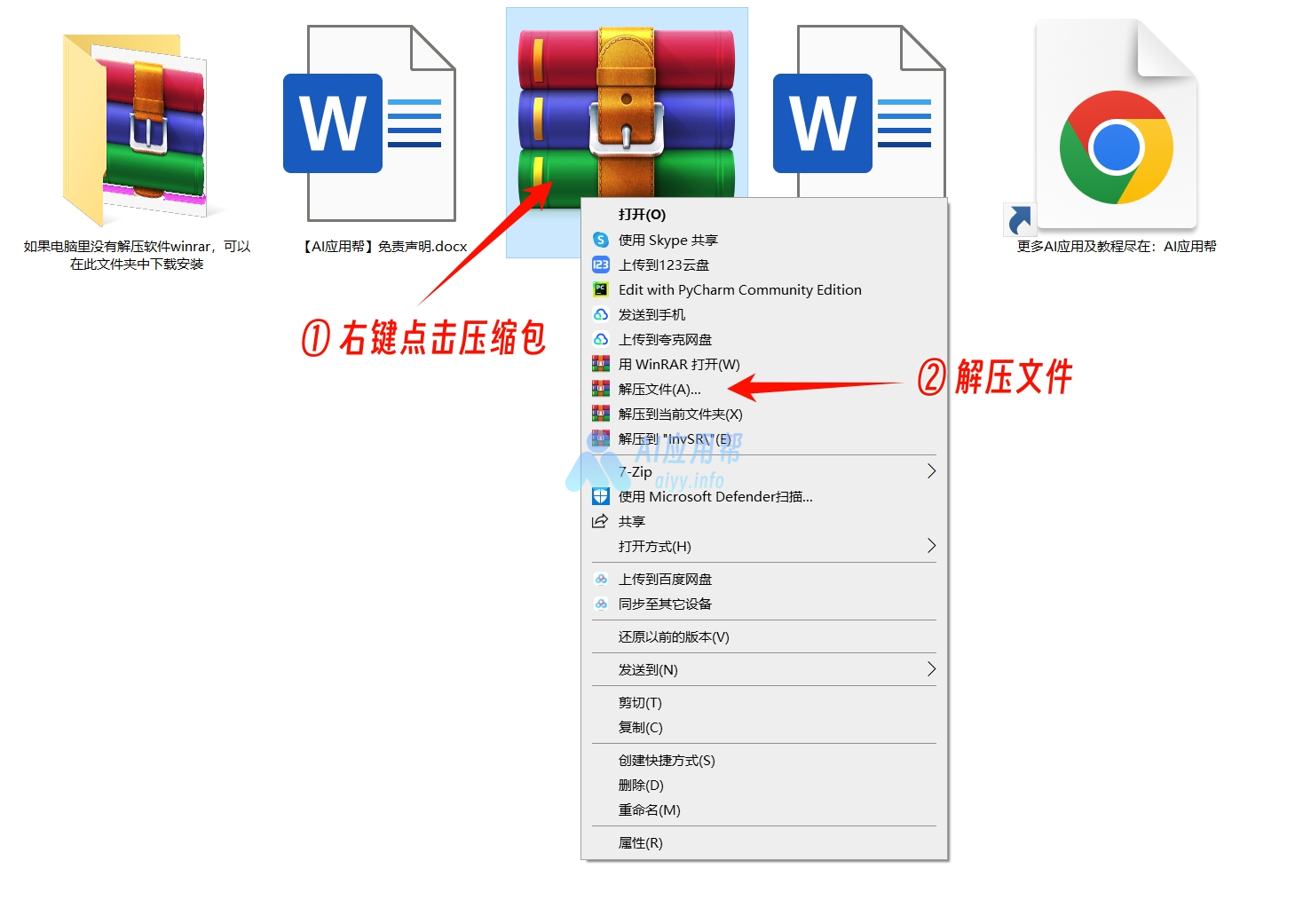
① 打开下载页面(https://aiyy.info/e2-f5-tts/)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

② 音频素材建议在15秒内,先处理音频,素材声音建议为干声(无背景音、无杂音),效果较佳,如果音频有背景音或者伴奏可以先用UVR处理一下
UVR使用教程及下载链接:https://aiyy.info/uvr5/
老版本:
③ 双击“一键启动.exe”,稍等片刻会在浏览器中自动打开操作界面
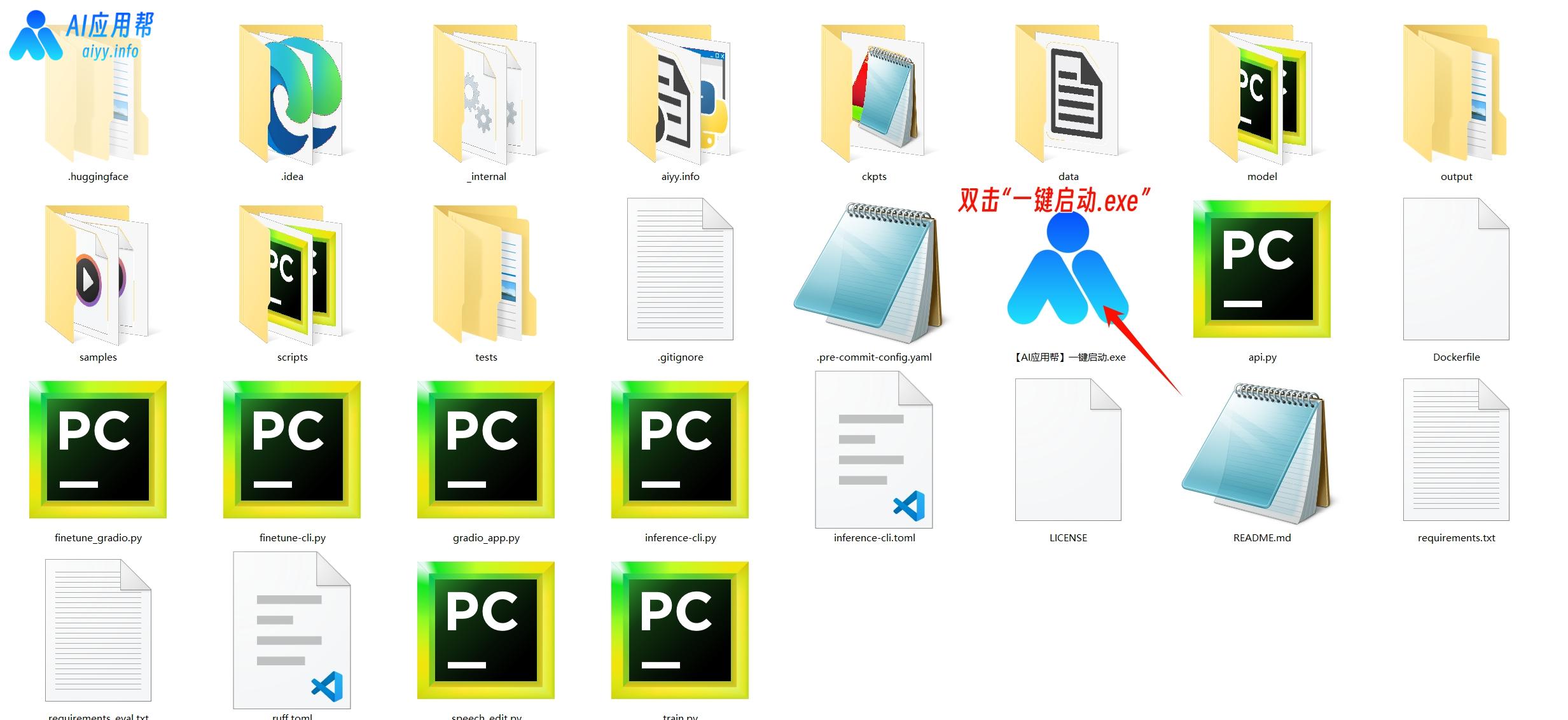
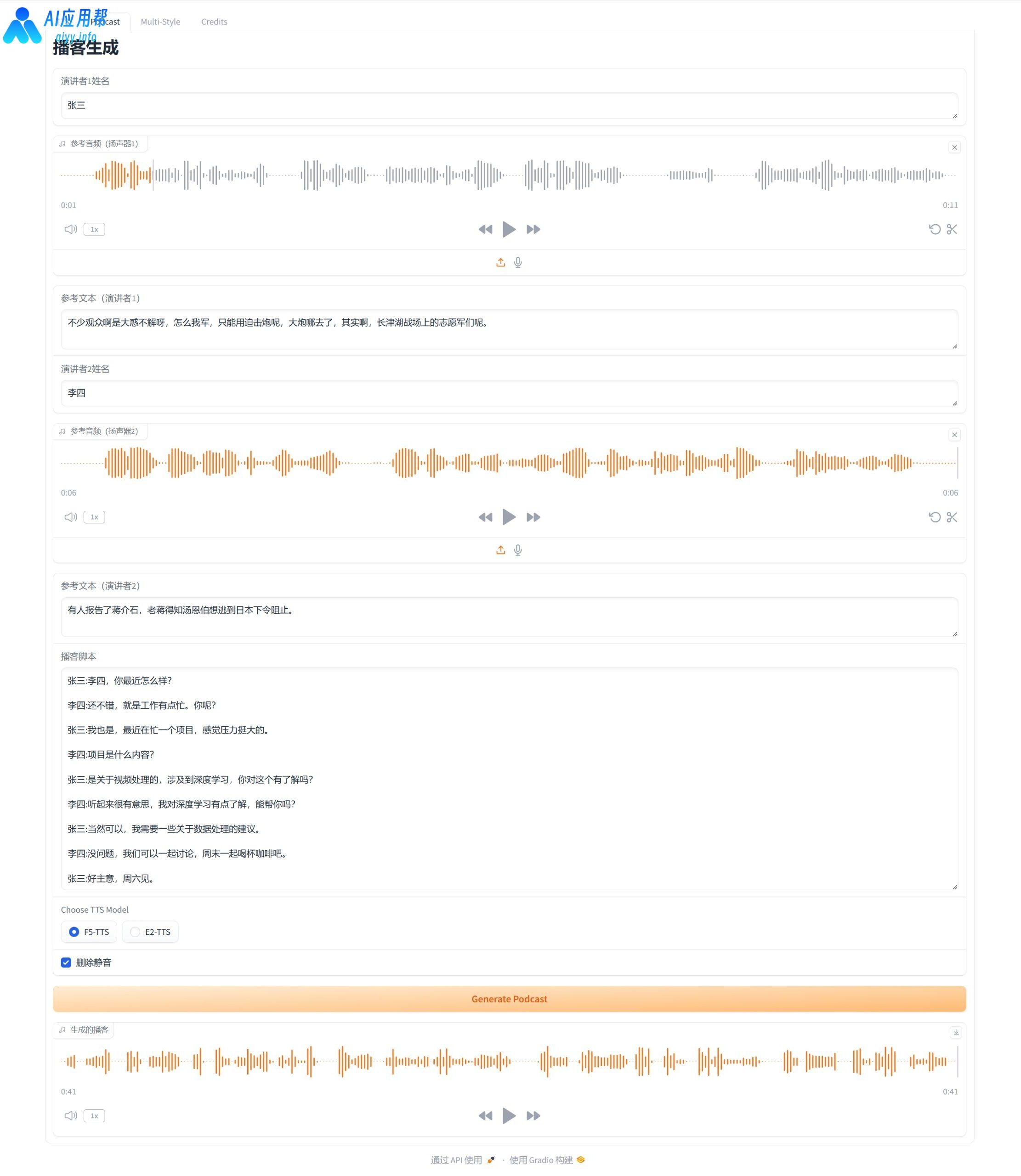
④ 单角色音频克隆并生成:
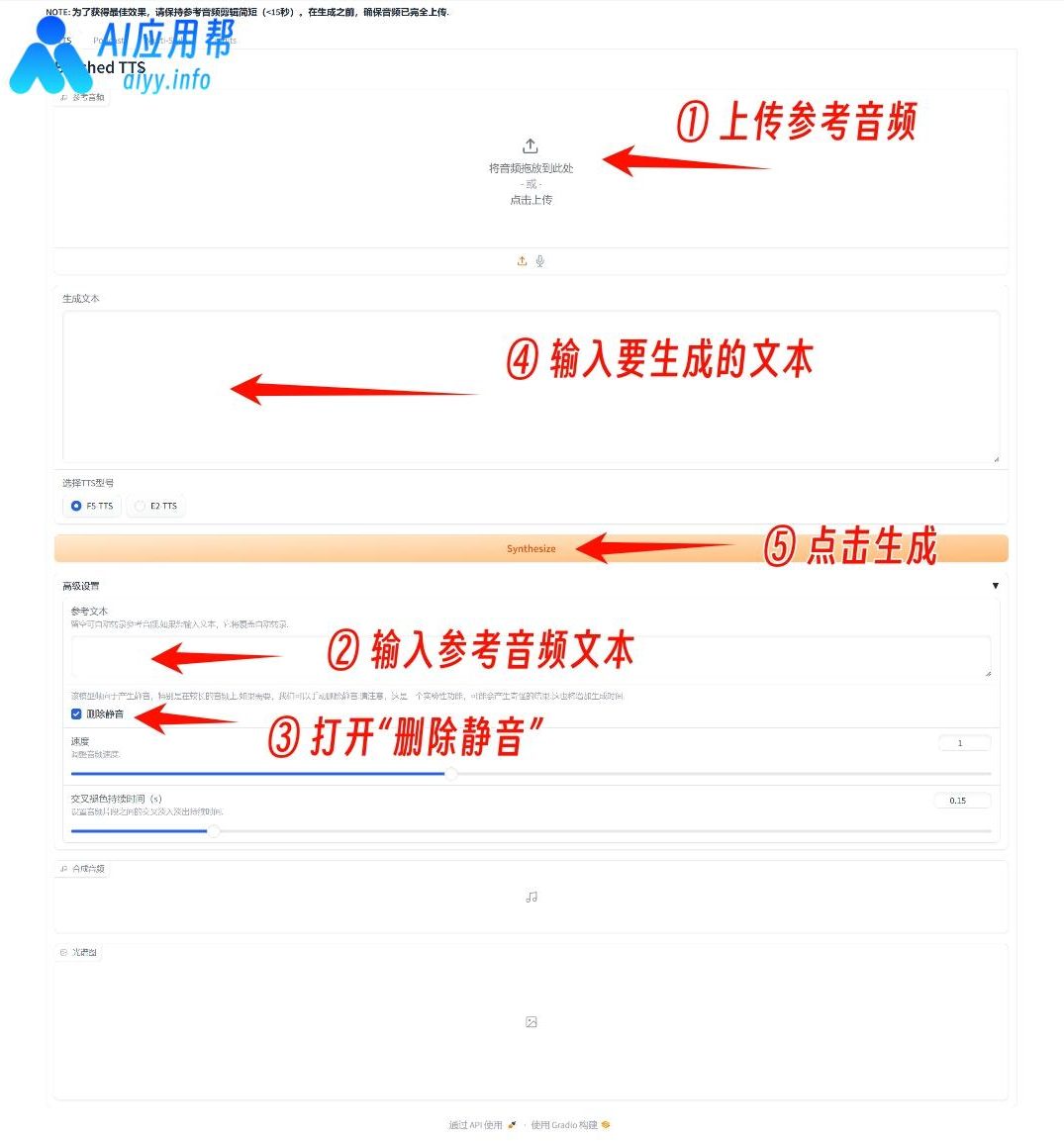
上传音频,再输入参考音频文本(就是音频的读白内容),再打开“删除静音”,输入要生成的文本,语句结尾加句号,最后点击生成
生成结束后,结果位于下方,可以试听,点击生成结果右上角下载按钮可以保存至指定文件夹
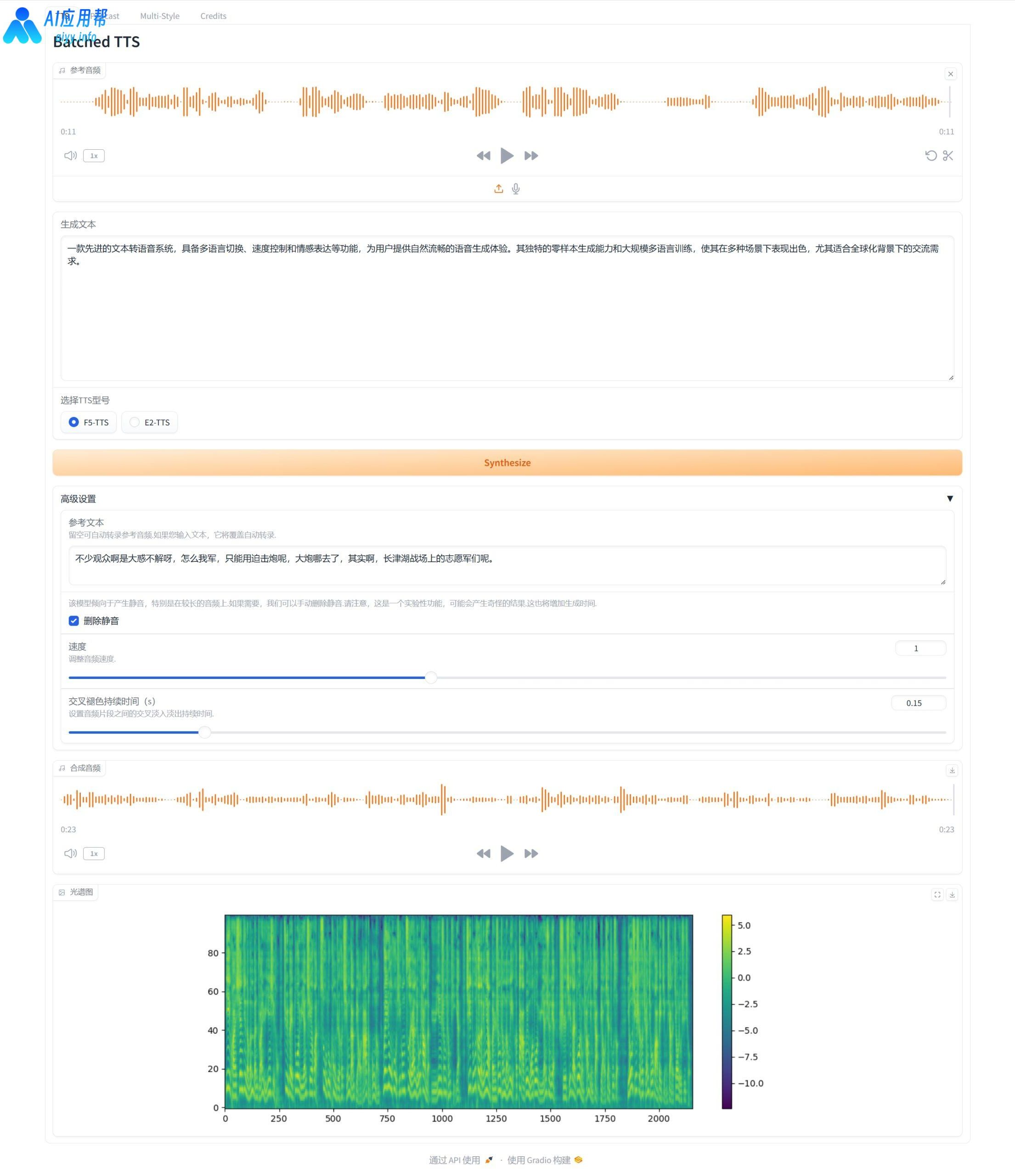
原音频:
生成结果:
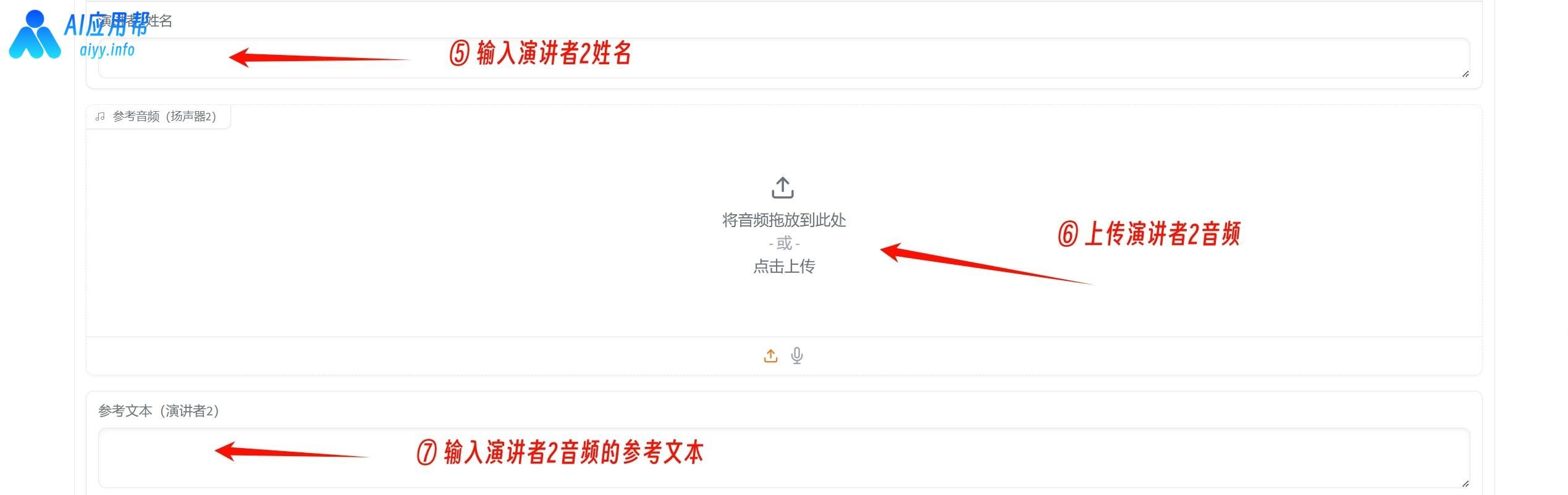
⑤ 双角色对话生成:
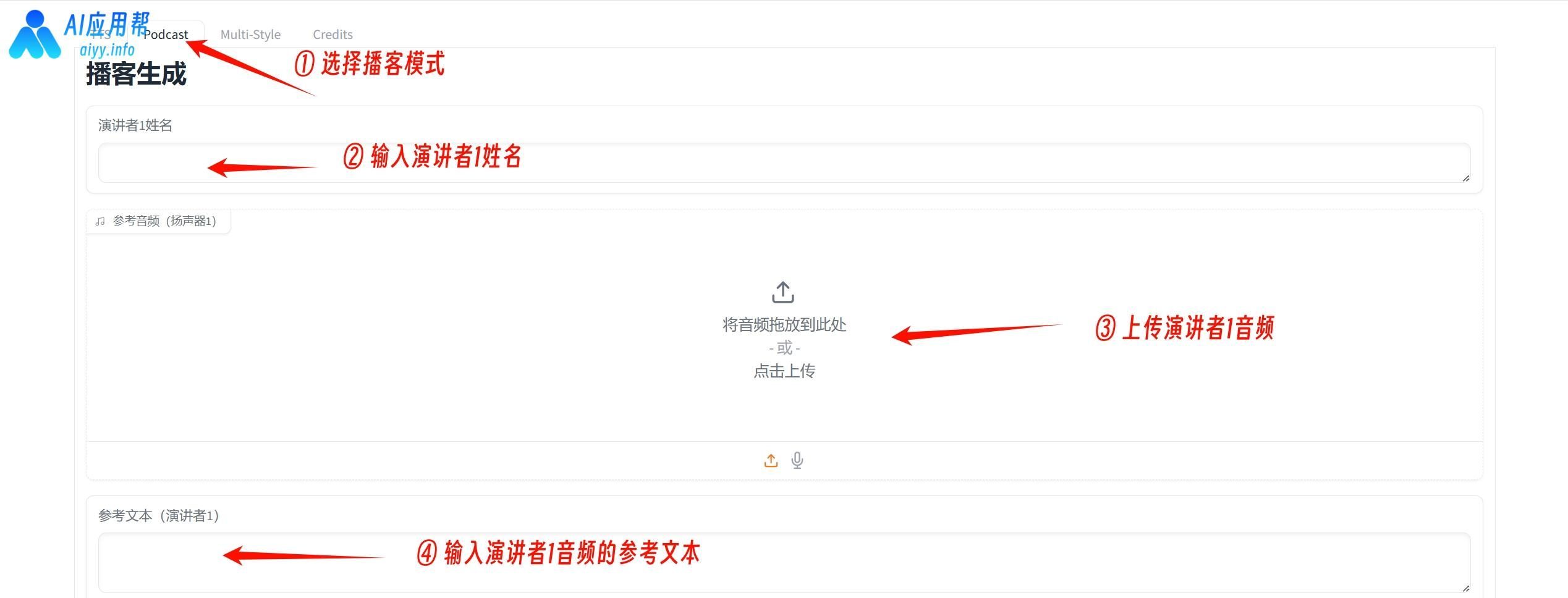
在上方选择“Podcast”播客模式,然后给角色命名并分别上传音频、输入音频参考文本(就是音频的读白内容)
先是输入演讲者1的姓名,然后上传演讲者1的音频,再输入演讲者1音频的参考文本(就是演讲者1音频的读白内容),接着输入演讲者2的姓名,然后上传演讲者2的音频,再输入演讲者2音频的参考文本(就是演讲者2音频的读白内容)。
编写播客脚本,姓名严格按照前面取的姓名,在姓名后面接英文冒号,然后写对话内容,每句话结束要加句号,否则容易造成生成内容缺失(可参考下方示例)
勾选删除静音,最后点击生成
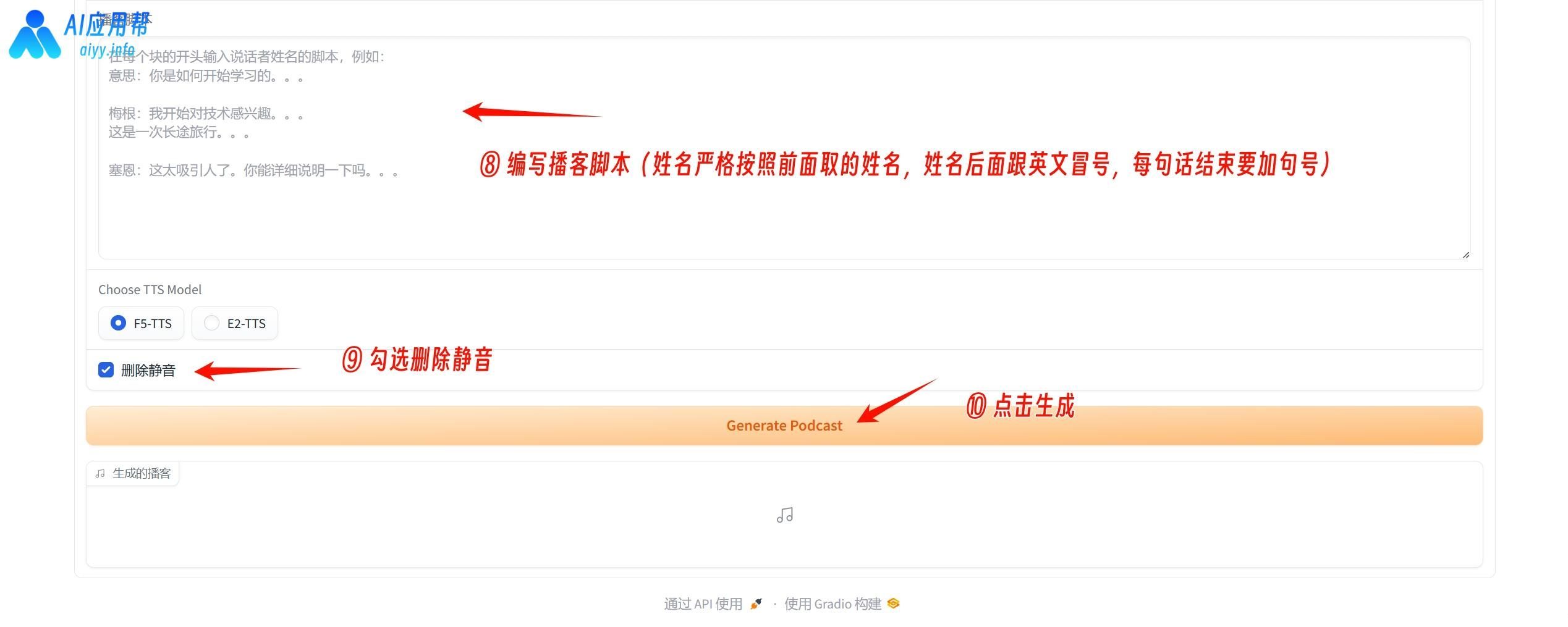
生成结束后,结果位于下方,可以试听,点击生成结果右上角下载按钮可以保存至指定文件夹
原音频-张三
原音频-李四
生成结果
此外工具还支持情绪生成,不过测试下来效果一般,就不做介绍了,大家有兴趣可以自行尝试