请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载
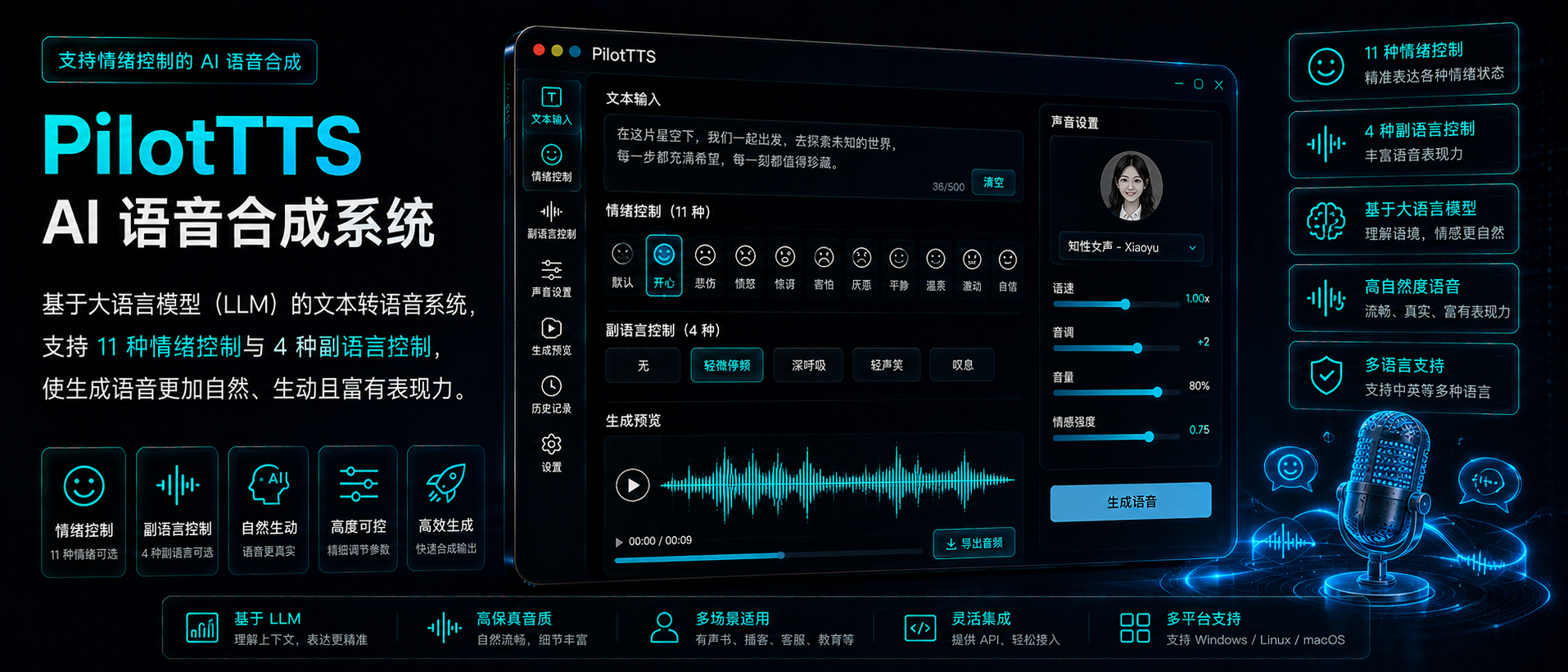
PilotTTS 是一款基于大语言模型(LLM)的文本转语音系统,采用“简化但高效”的架构设计,在完全开源组件基础上,通过高质量数据工程实现了接近业界顶级水平的语音生成效果。相比依赖复杂闭源流程的传统 TTS 系统,PilotTTS 更强调开放性、可控性与高质量训练数据构建。
该系统不仅在说话人相似度与文本内容准确率方面表现出色,还支持丰富的情绪与副语言控制,使生成语音更加自然、生动且富有表现力。
核心功能:
- 🗣️ 高质量文本转语音(TTS):生成自然流畅的人声语音
- 👤 高相似度语音克隆:精准还原目标说话人音色
- 📝 内容一致性控制:降低发音错误与文本偏差
- 🎭 情绪控制生成:支持 11 种情绪类别
- 🔊 副语言控制:支持笑声、呼吸、哭泣、咳嗽等表达
- 🔓 全开源数据处理流程:完整公开的数据清洗与标注管线
支持情绪类别:
Happy、Sad、Fear、Angry、Surprise、Serious、Concern 等 11 种情绪表达。
支持副语言控制:
LAUGH(笑声)、BREATH(呼吸)、CRY(哭泣)、COUGH(咳嗽)等。
技术亮点:
- 🧠 基于 LLM 的语音生成架构
- 📦 全开源数据工程与处理流程
- 🎯 Seed-TTS 测试集上达到 SOTA 级说话人相似度
- 🪶 降低高质量 TTS 数据构建成本
应用场景:
- AI 数字人与虚拟主播
- 有声书与播客生成
- 游戏角色配音
- AI 情感语音交互
- 视频旁白与内容创作
开源地址:https://github.com/AMAPVOICE/PilotTTS
☞☞☞☞☞☞ 右侧下载整合包 ☞☞☞☞☞☞
配置要求:
电脑需满足以下配置:
- 操作系统:Windows 10/11 64位
- 内存:建议16G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡
- CUDA:显卡支持的CUDA版本大于等于12.8版本(如不知道显卡支持的CUDA版本,可点击此链接查看:https://aiyy.info/supported-cuda-versions/)
- 整个包解压完约26.7G,要留足硬盘空间
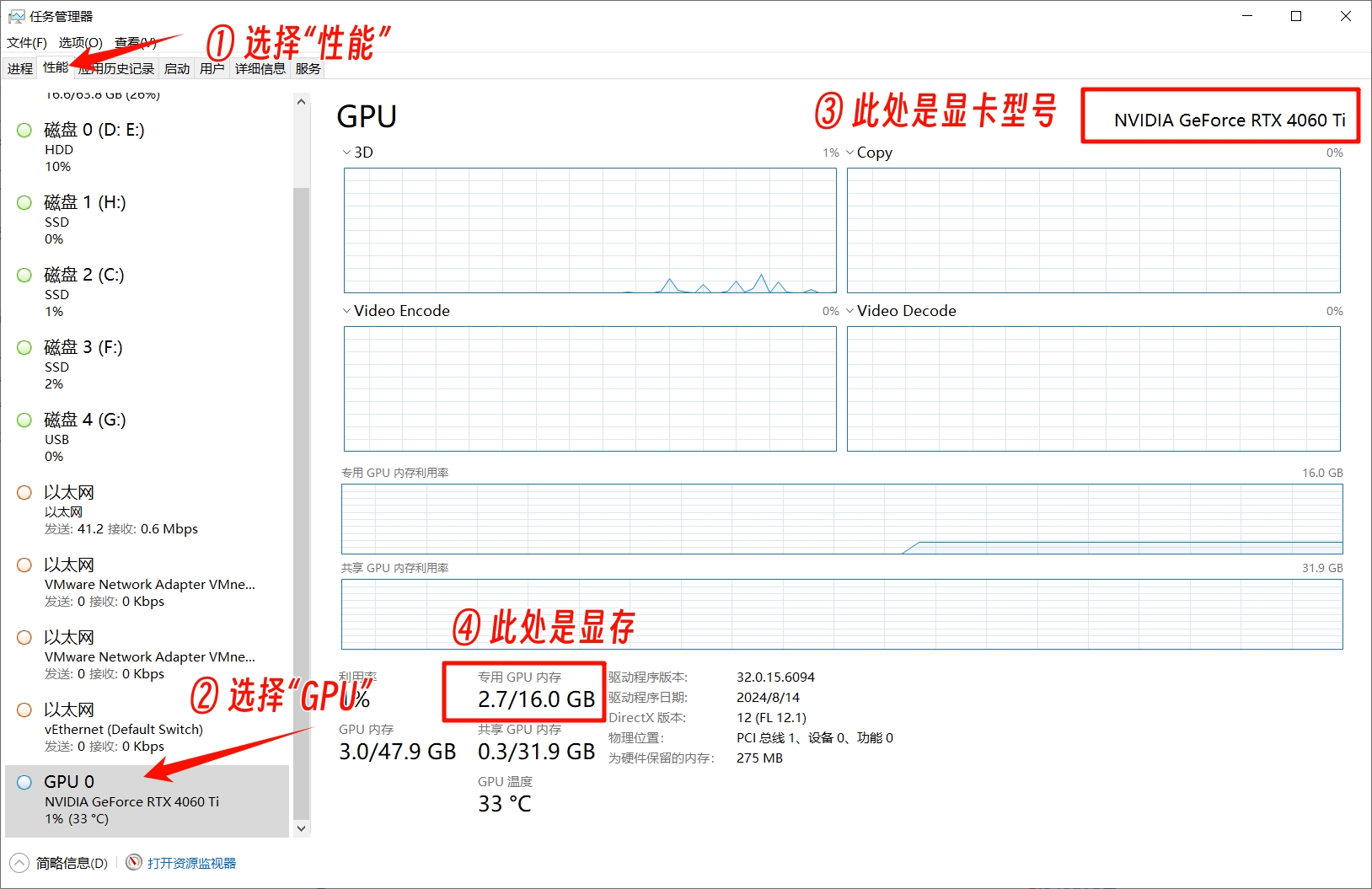
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
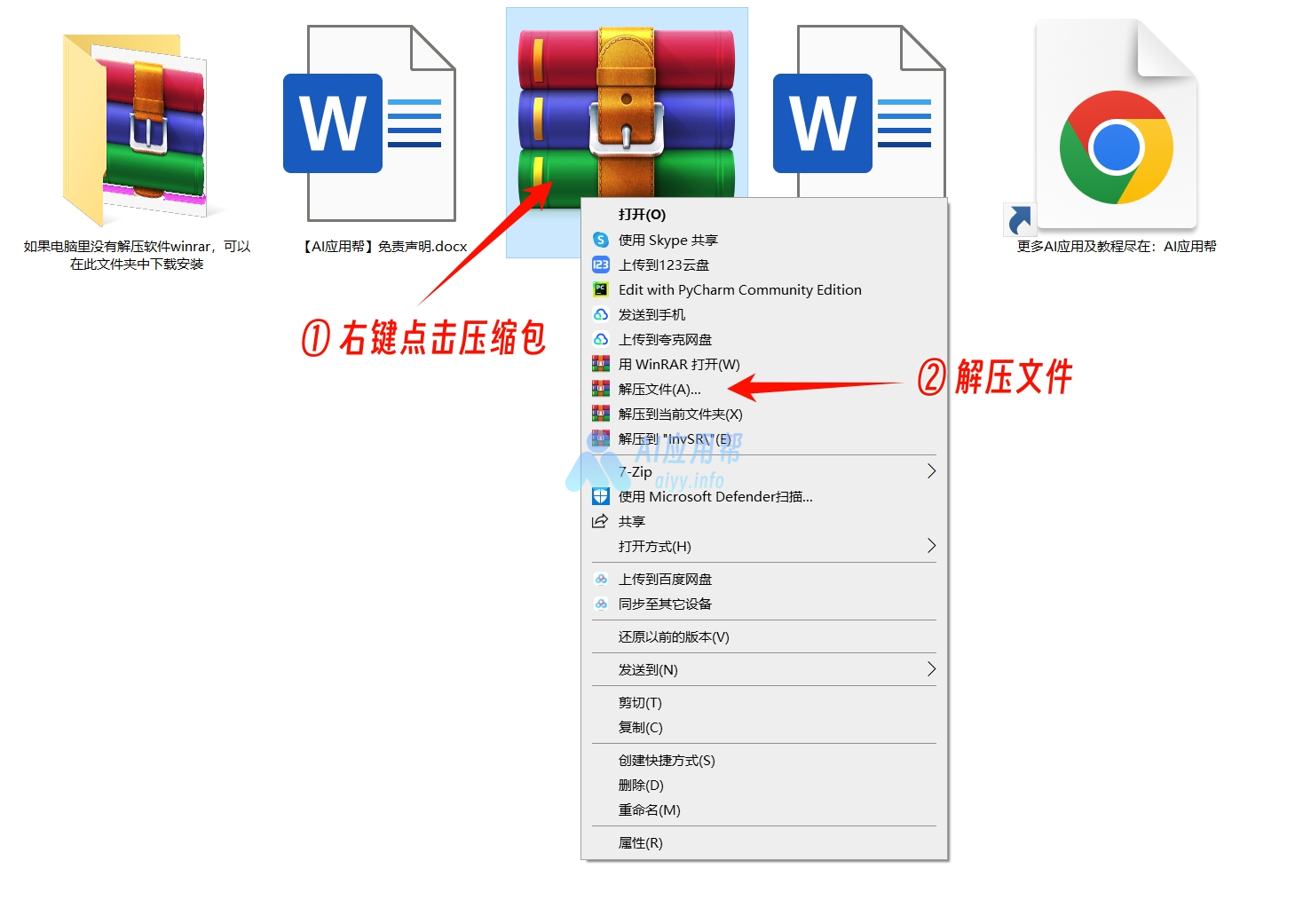
① 打开下载页面(https://aiyy.info/pilottts/)点击页面右侧下载按钮(手机端在页面底部),下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

② 双击“一键启动.bat”,稍等片刻会在浏览器中自动打开操作界面
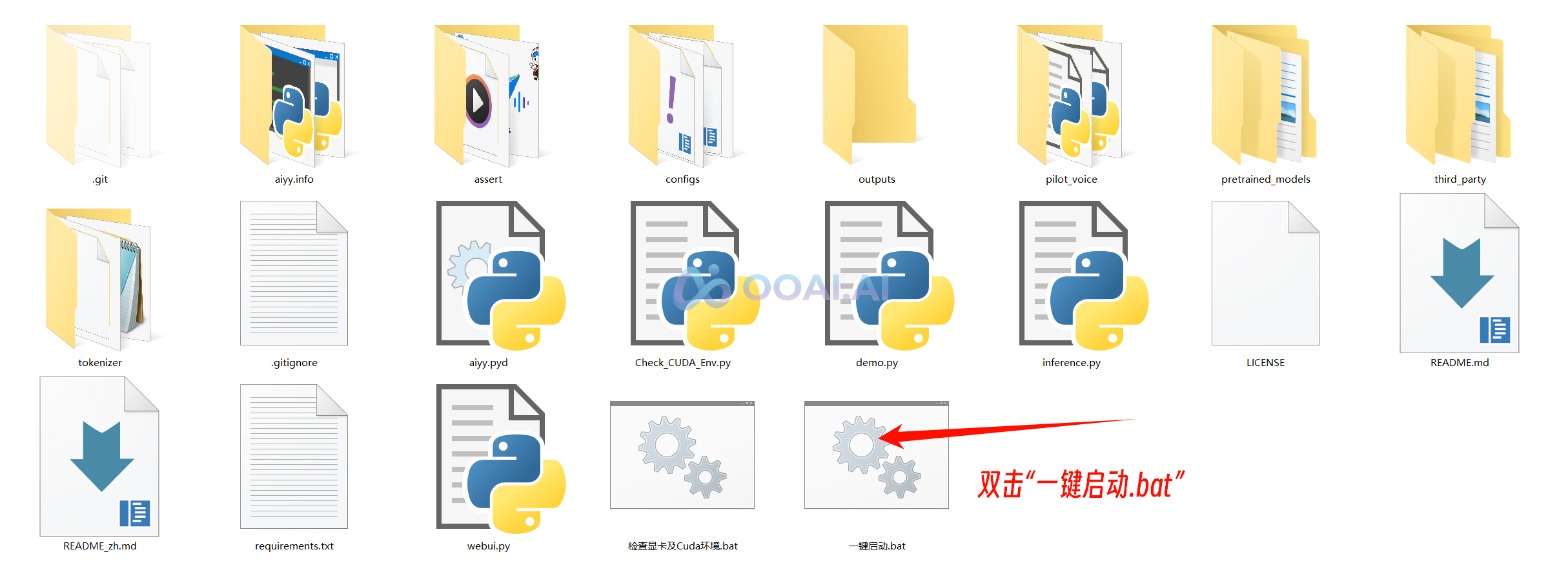
③ 零样本克隆:使用基础模型,根据参考音频克隆音色并朗读目标文本,无需额外标注。
添加参考音频,输入需要合成的文本,然后点击“开始合成”即可
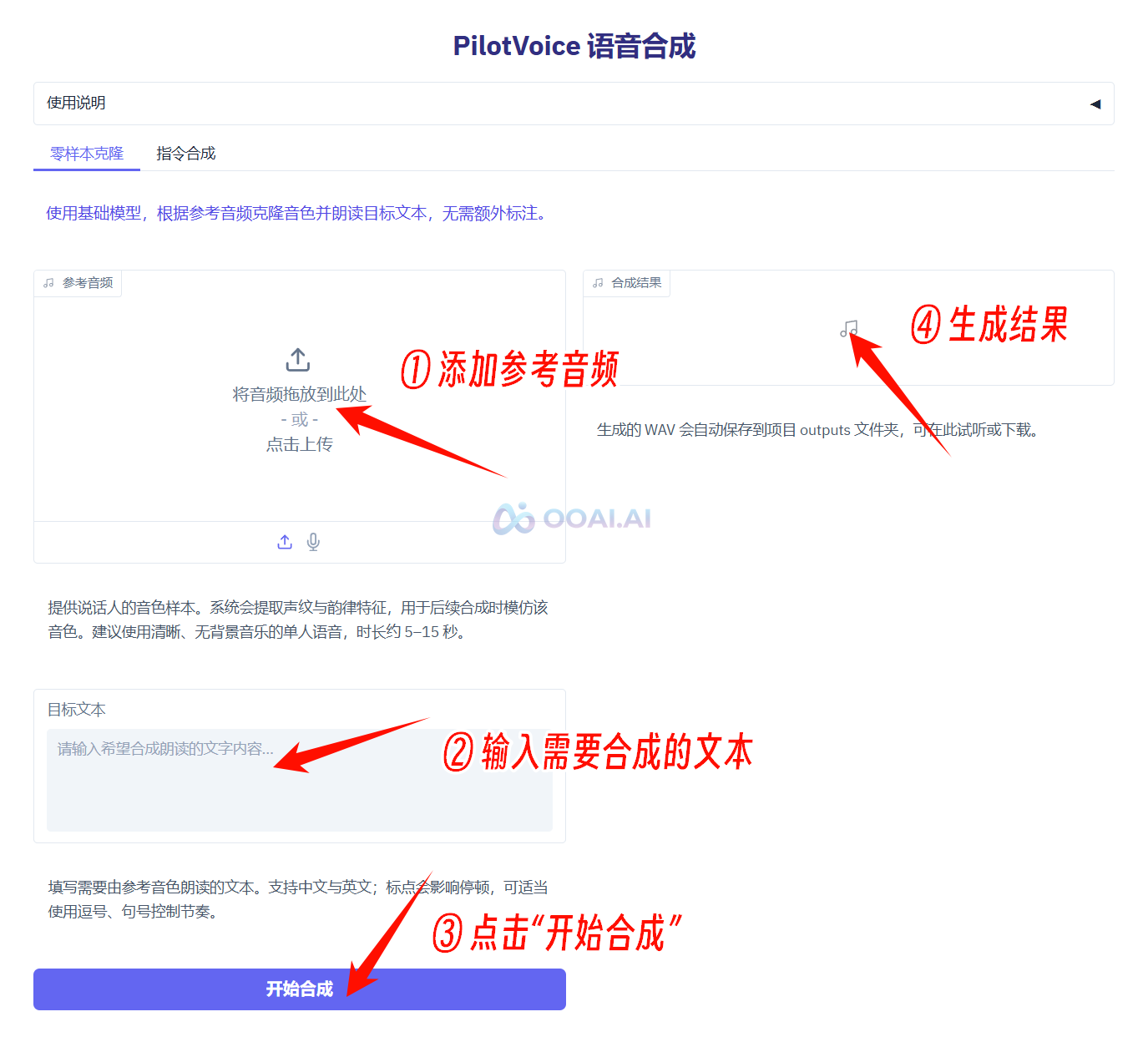
生成结果位于右侧, 可以播放试听,点击下载按钮可以保存至指定文件夹
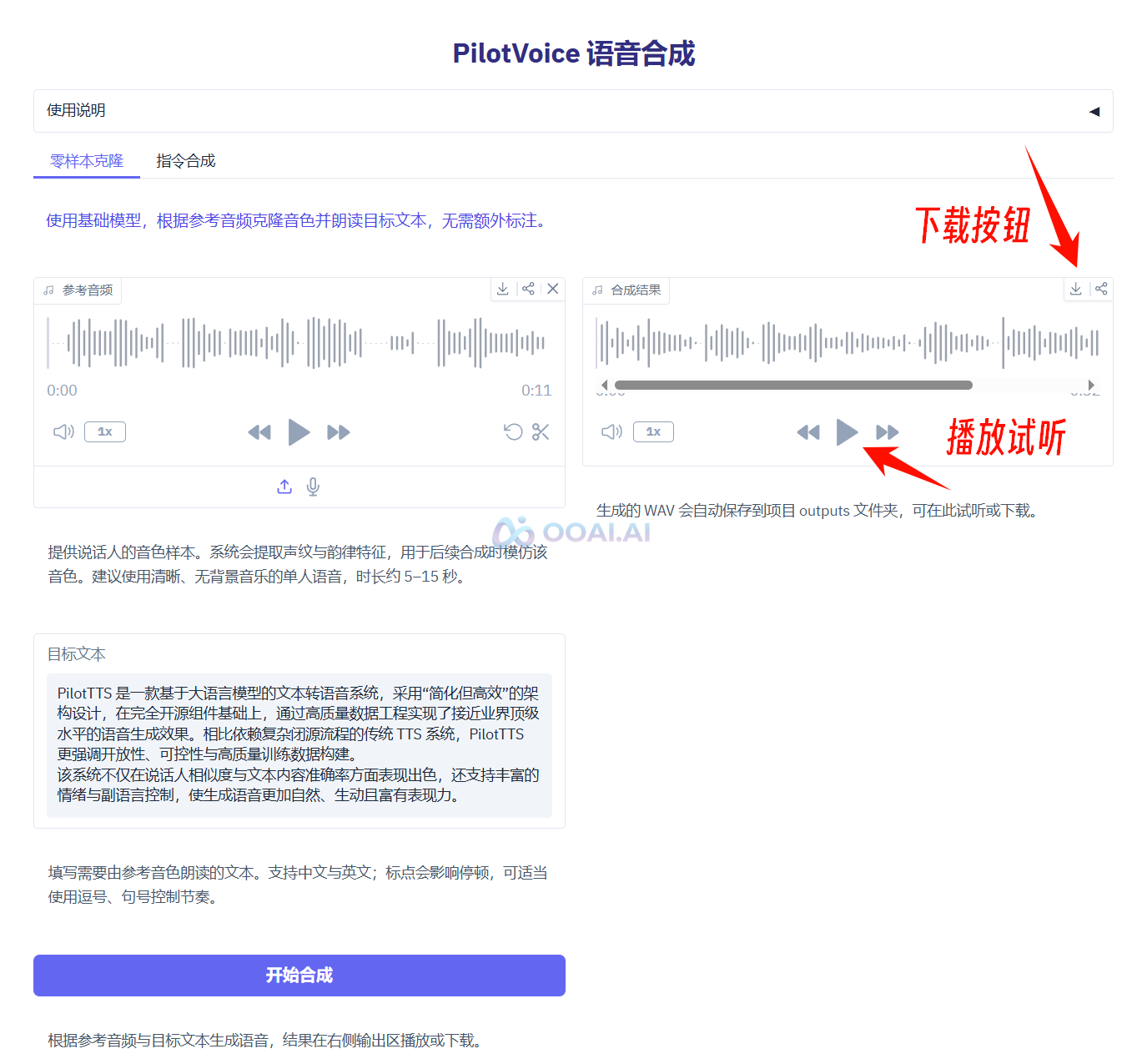
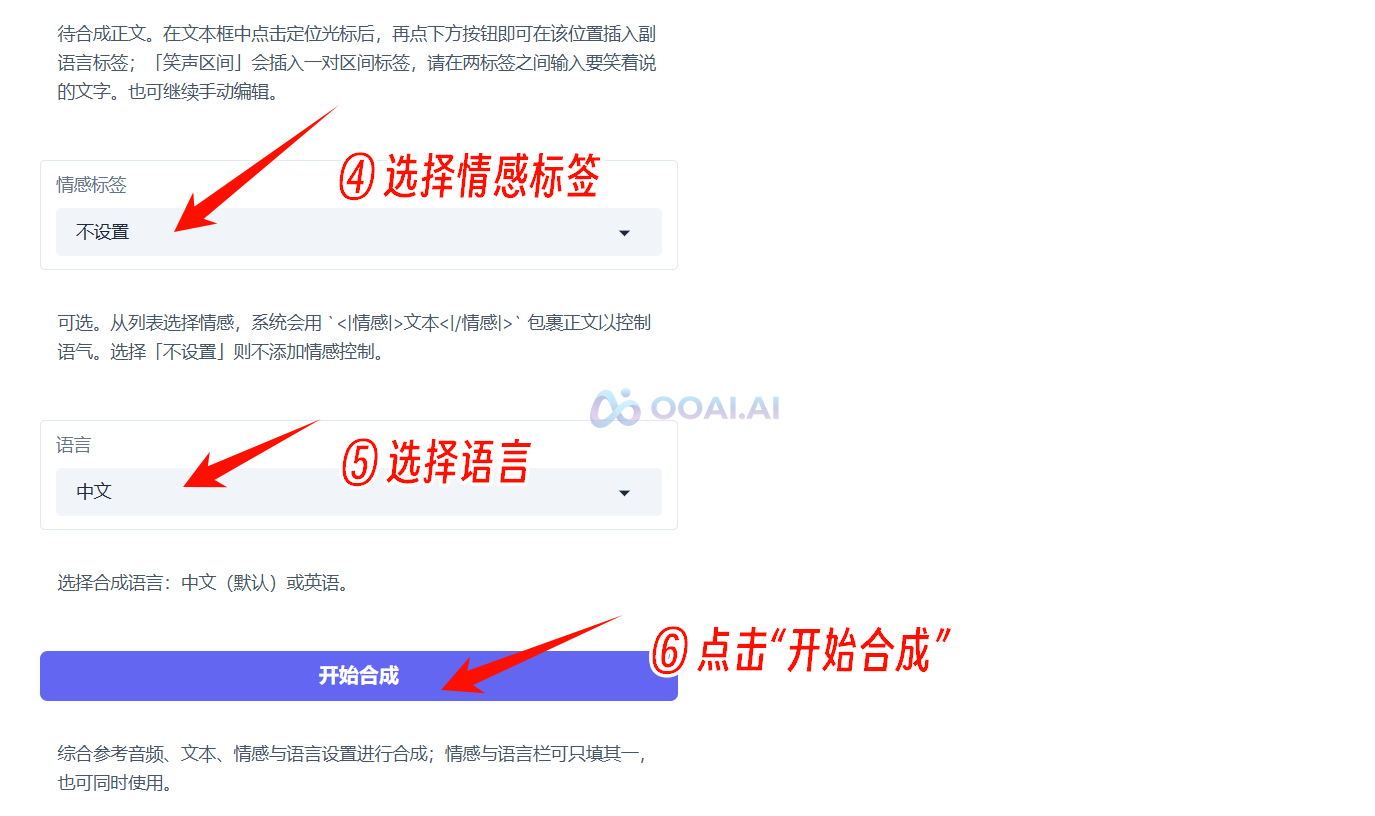
④ 指令合成:使用指令模型,在克隆音色的同时控制情感、副语言事件或语言(中文/英语)。
添加参考音频,输入需要合成的文本,可以在文本中添加副语言标签(支持笑声、换气、咳嗽、哭泣等),可以选择情感标签(支持开心、悲伤、愤怒、惊讶、恐惧、厌恶、严肃、关切、忧郁、轻蔑、中性/平静、心理活动等),选择语言(中文/英文),然后点击“开始合成”即可
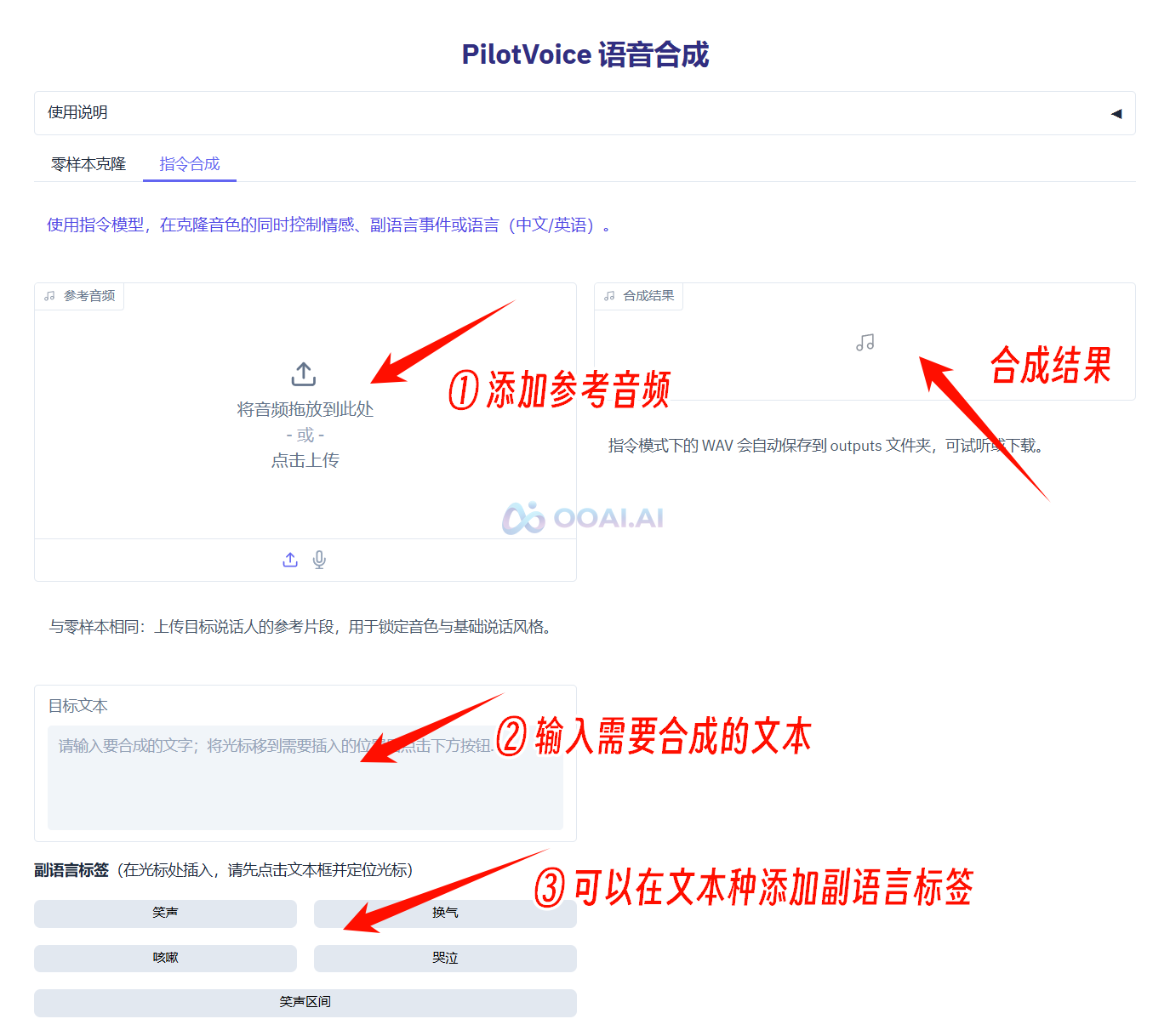
生成结果位于右侧, 可以播放试听,点击下载按钮可以保存至指定文件夹

⑤ 在文件包中的“outputs”文件夹中也能找到生成结果