
请先查看下方配置要求,确认电脑能使用再下载,如果不知道什么是网盘、什么是压缩包以及什么是电脑配置,请勿下载

Stable Audio 3 是新一代开源 AI 音频与音乐生成平台,专注于高速、高质量、可编辑的音频生成体验。该系列基于潜空间扩散模型(Latent Diffusion)构建,提供 small、medium、large 多种模型规模,支持变量时长音频生成、音频编辑与局部修复,并针对推理效率进行了深度优化。
相比传统音频扩散模型,Stable Audio 3 引入了全新的语义-声学自动编码器(Semantic-Acoustic Autoencoder),能够将音频压缩到高效潜空间中,在保持音质的同时提升语义结构表达能力,从而实现更快、更稳定的生成效果。
核心功能:
🎵 高质量音乐与音效生成:支持多种风格音乐与环境音生成
⏱️ 可变时长生成:无需固定生成完整长音频,更高效灵活
✂️ 音频局部重绘(Inpainting):可精准编辑指定音频片段
🔄 音频续写与扩展:延续已有录音生成后续内容
💻 消费级硬件支持:Small / Medium 模型可在普通显卡与 MacBook 上运行
技术亮点:
🧠 潜空间扩散架构(Latent Diffusion):兼顾速度与音质
🎚️ 语义-声学自动编码器:提升音频语义理解与细节保真
🚀 对抗式后训练优化:减少推理步数并提升 Prompt 遵循能力
📦 完整训练与推理管线开源:便于开发者微调与二次开发
应用场景:
AI 音乐创作
视频 / 游戏配乐
环境音与音效制作
音频修复与续写
AI 内容生成平台与创意工具
开源地址:https://github.com/Stability-AI/stable-audio-3
☞☞☞☞☞☞ 右侧下载整合包 ☞☞☞☞☞☞
配置要求:
电脑需满足以下配置:
- 操作系统:Windows 10/11 64位
- 内存:建议16G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡
- CUDA:显卡支持的CUDA版本大于等于12.8版本(如不知道显卡支持的CUDA版本,可点击此链接查看:https://aiyy.info/supported-cuda-versions/)
- 整个包解压完约21.8G,要留足硬盘空间
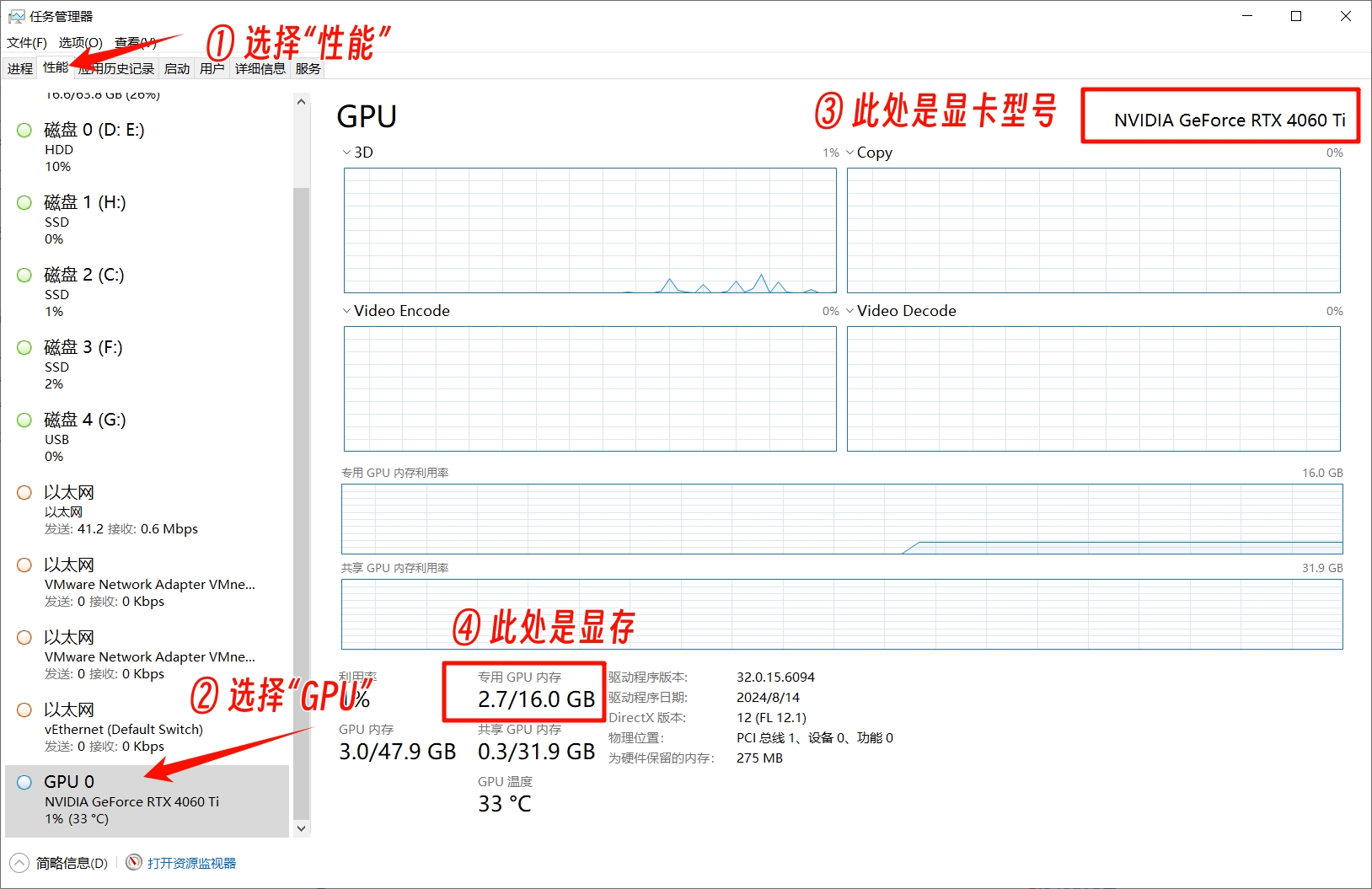
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
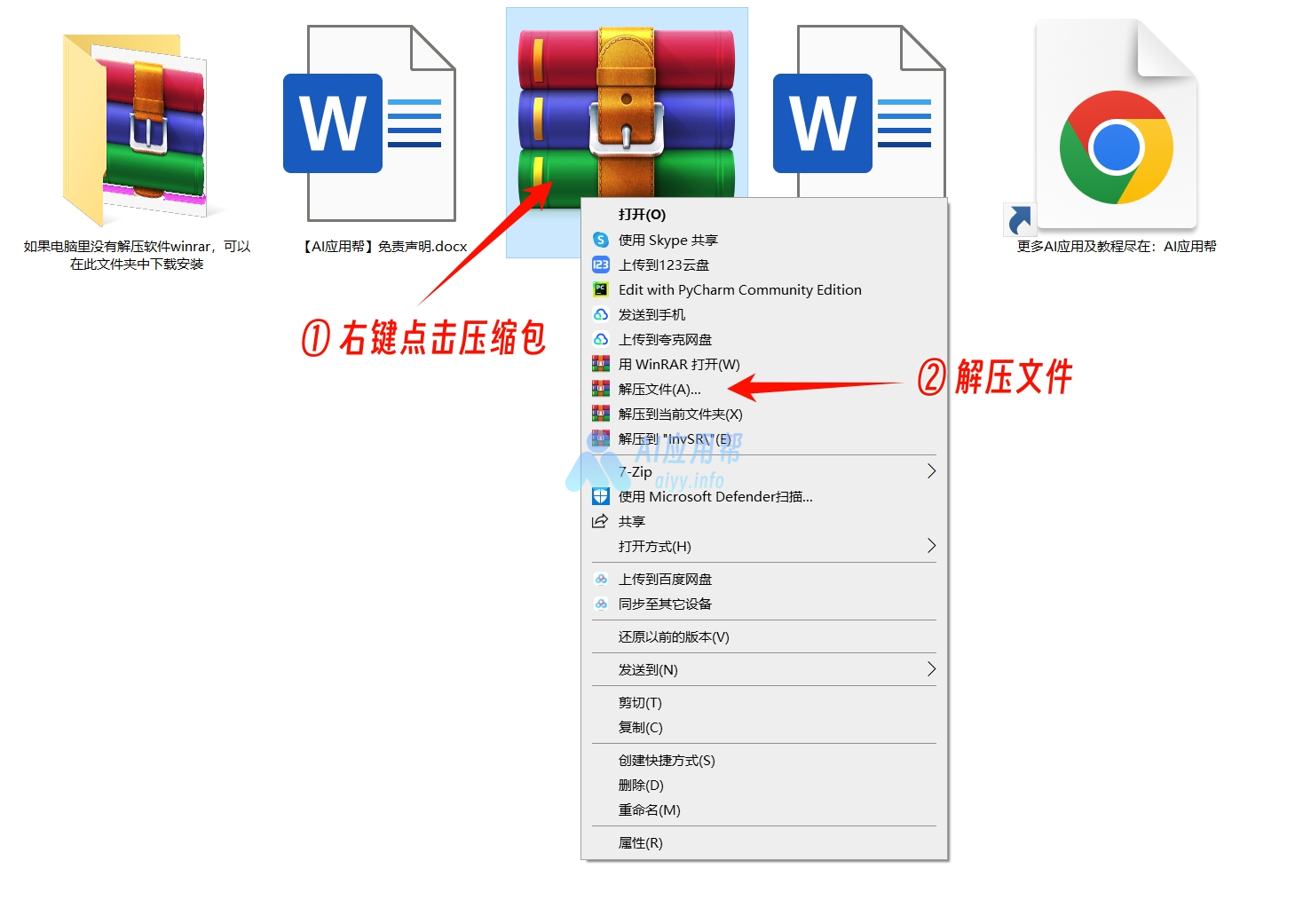
① 打开下载页面(https://aiyy.info/stable-audio-3/)点击页面右侧下载按钮(手机端在页面底部),下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错

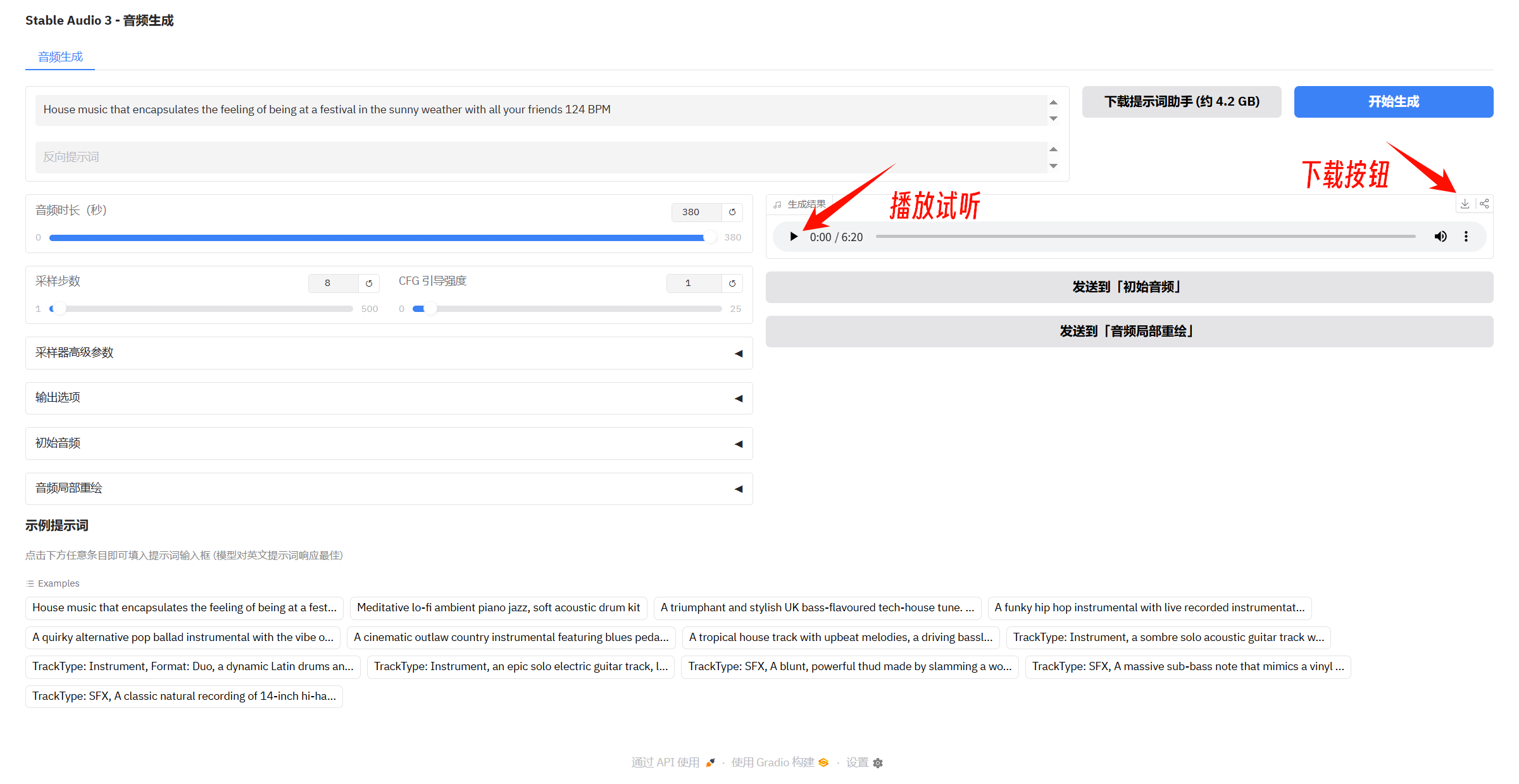
② 双击“一键启动.bat”,稍等片刻会在浏览器中自动打开操作界面
③ 输入提示词(建议使用英文输入效果较佳),调整音频时长,点击“开始生成”即可
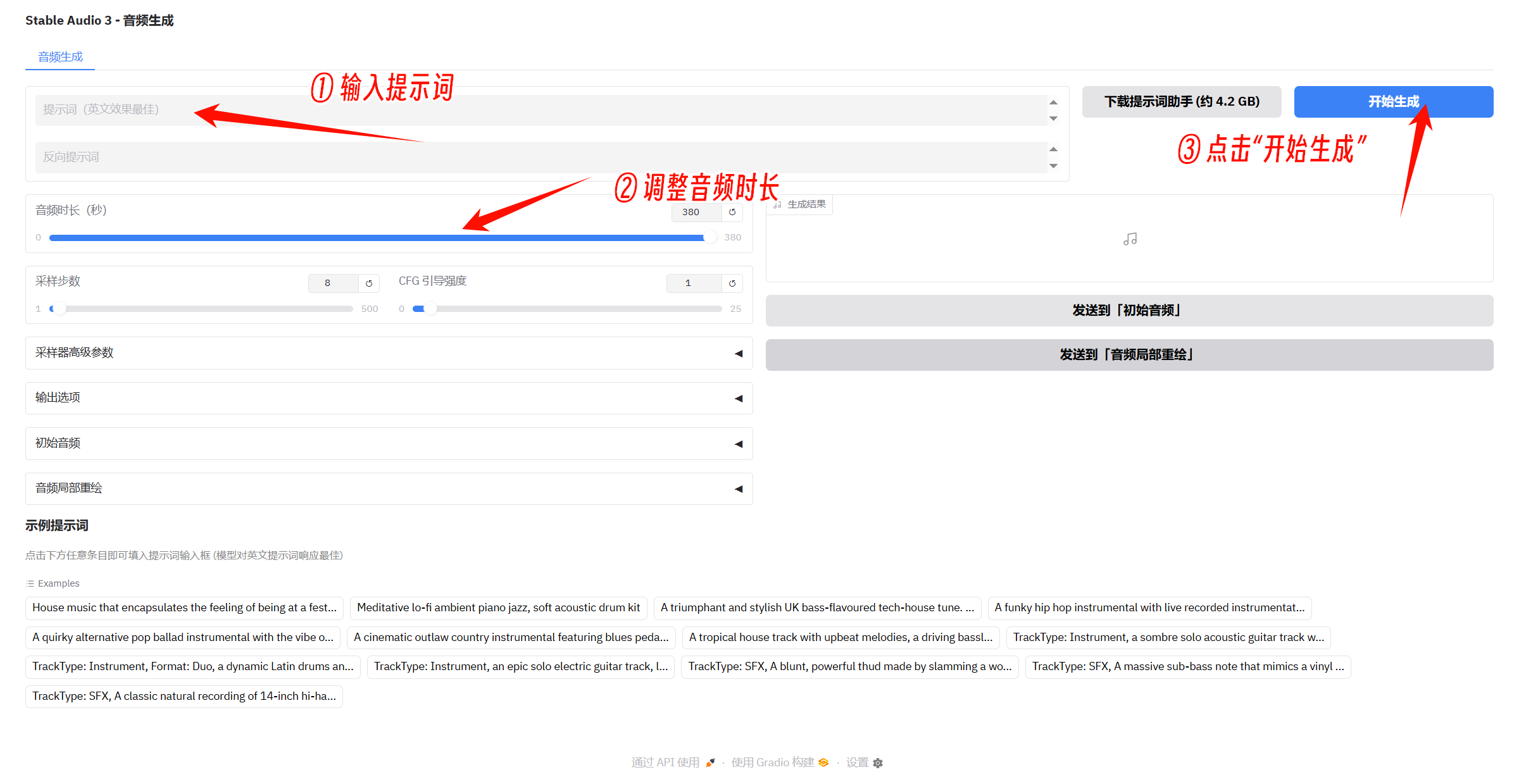
④ 生成结果位于右侧,可以播放试听,点击下载按钮可以保存至指定文件夹
⑤ 在文件包中的“outputs”文件夹中也能找到生成结果


